如今,AI 的火热程度已经不需要解释。算力、算法、数据,构成驱动 AI 技术快速发展的三驾马车:
完整的 AI 训练包括数据收集、数据预处理、数据标注、数据分割、模型设计、模型搭建、模型训练、模型评估、模型调优,最终部署等环节。GPU 作为整个模型训练的算力核心,因其成本高昂,系统架构和参数设置应以最大发挥 GPU 的使用频率为目标。
模型训练阶段,SSD 通常用于提供 GPU 所需的样本数据,并对 GPU 训练产生的中间结果、日志、临时文件等加以保存。随着数据量的爆炸式增长,高效的数据摄取和处理成为一项重大挑战。为探究 SSD 对模型训练带来的影响,本文将通过 DLIO Benchmark 测试软件进行验证。
由于本文篇幅较长,为方便阅读,这里先放结论:
以下是测试详情。
DLIO Benchmark 是行业里非常有名的,针对深度学习应用负载的 I/O 性能检测工具。它通过模拟训练过程中的 I/O 行为,帮助开发人员快速找到系统架构中的 I/O 瓶颈,并指导优化训练性能。
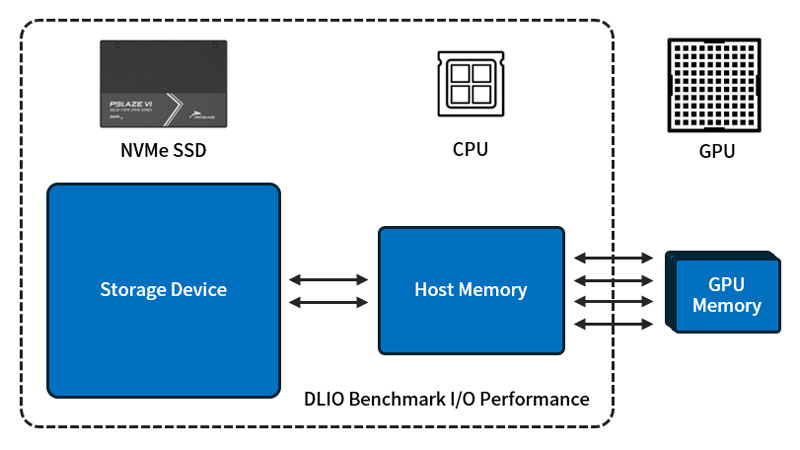
如图所示,在硬件架构中,硬盘、系统内存、GPU 都不应存在瓶颈。数据供给不及时,将造成 GPU 等待;GPU 性能弱,数据请求也会相应减少。
DLIO Benchmark 的测试涵盖多种深度学习模型任务,如图像分类、自然语言处理、宇宙结构探究等等。通过这些测试,我们可以得到基于具体的硬件配置和运行参数,在不同深度学习框架,如 TensorFlow、PyTorch 等,在特定任务上的 I/O 性能表现。
DLIO Benchmark 内置了多个标准模型训练任务脚本,包括:
测试使用的环境如下:
测试使用 UNet3D 脚本,模拟20,480个样本文件的训练过程。由于样本体积达到3TB,远超系统内存,系统会将它们分多个批次加载 —— 当 GPU 取走一批数据,SSD 需要在 GPU 完成这批数据的训练前将下一批数据写进内存,会比较考验 SSD 的读性能。
每一个模拟训练均执行5个 epoch,每个 epoch 结束重新加载训练样本集,对内存中已经缓存的近 500GB 数据进行更新。由于样本加载顺序随机,少量样本可能会命中缓存,带来小幅 I/O 性能提升。当然,如果系统内存“足够大”,可以包容全部样本数据,对 I/O 性能的提升将会非常明显,但成本也会大幅增加。
这里我们使用 DLIO Benchmark 软件分别模拟 1、2、4、6、8、16、32颗 GPU 的配置情况。
通过模拟 AI 模型训练及其数据加载行为,我们可以统计出配置不同的 SSD、不同数量的 GPU,其训练环节的耗时差异,结果如下:
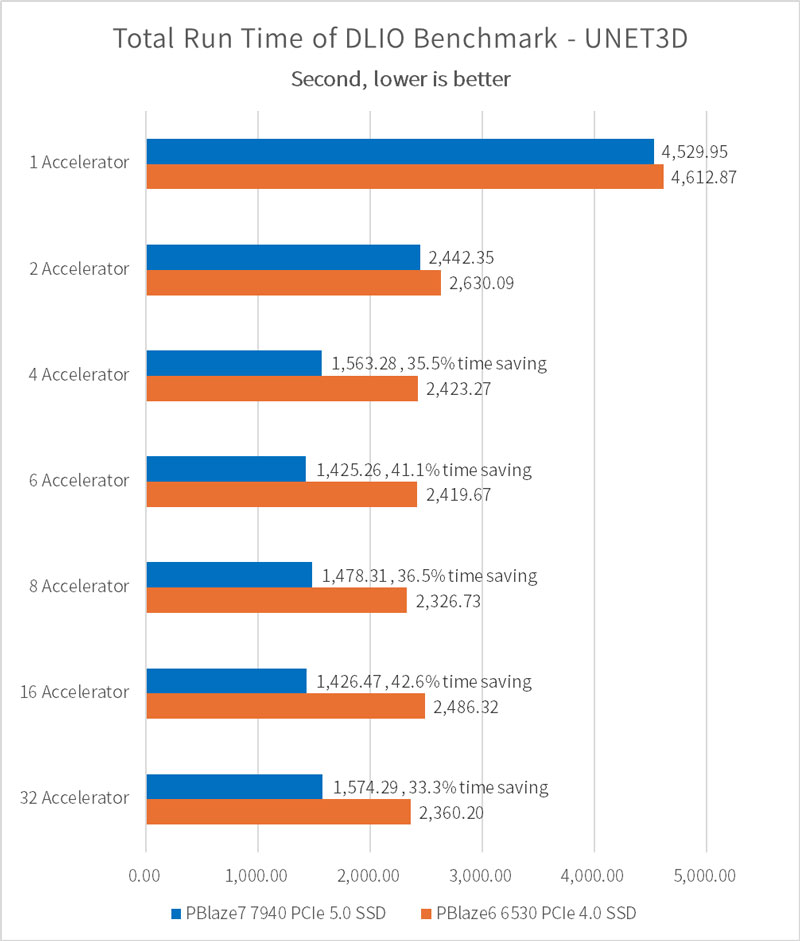
在 epoch=5 的情况下,通过配置单片 PBlaze7 7940 PCIe 5.0 SSD,可以在4颗或更多 GPU 的训练任务中,相比 PCIe 4.0 SSD 节省近1,000秒的时间。我们假设80个 epoch 为一次完整训练,节省时间则可以达到 16,000秒,并在80次完整训练下节省14.8天!
当加速器(GPU)数量设置为1时,由 PBlaze7 7940 PCIe 5.0 SSD 和 PBlaze6 6530 PCIe 4.0 SSD 构成的训练平台均可以带来 3.1GB/s 的 I/O 性能。根据平均样本文件体积 146MB、每个加速器一次加载样本数量32个,以及 V100 GPU 的计算环节代替参数,可得出加速器理论处理上限为 3400MB/s,远没有达到 SSD 和系统内存的读带宽。因此,我们可以继续增加加速器(GPU)的数量,在不增加服务器的情况下继续提升训练性能。
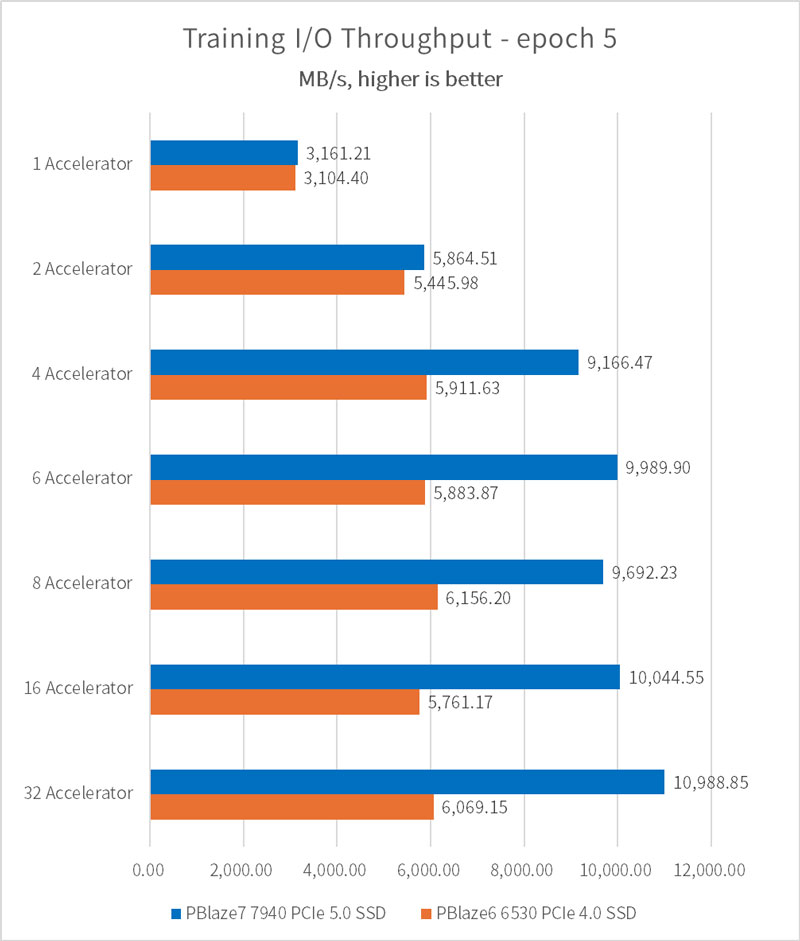
在配置4颗加速器的情况下,PBlaze7 7940 PCIe 5.0 SSD 训练平台可以提供 9.16GB/s 的 I/O 性能;在配置6颗加速器的情况下,CPU、内存开始出现长时间满载情况,I/O 性能收益也开始下降,最终 I/O 性能为 10.98GB/s。
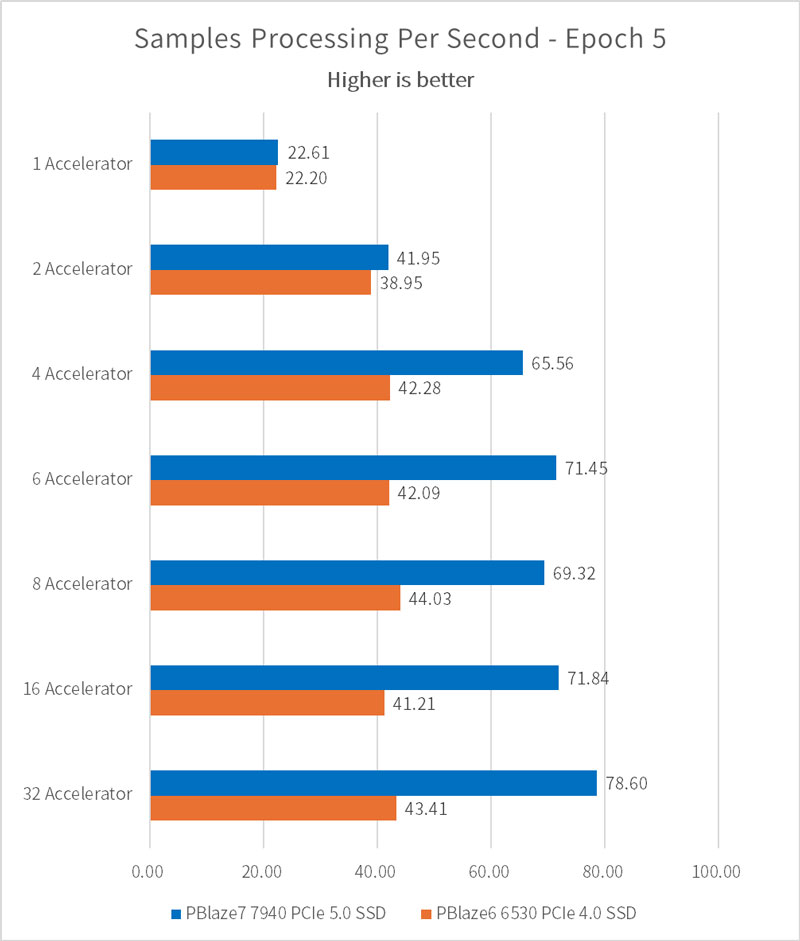
每秒样本处理数量和 I/O 性能测试结果一致,数值越大,意味着模型训练的速度越高。
Accelerator Utilization 代表加速器(GPU)的利用效率,当加速器数量较少时,由 PBlaze7 7940 组建的训练平台可满足加速器对数据的请求,此时加速器利用率较高,达到 98.77%;当加速器数量较多时,每一个加速器获得的 I/O 传输带宽变少,使用效率也出现下降。
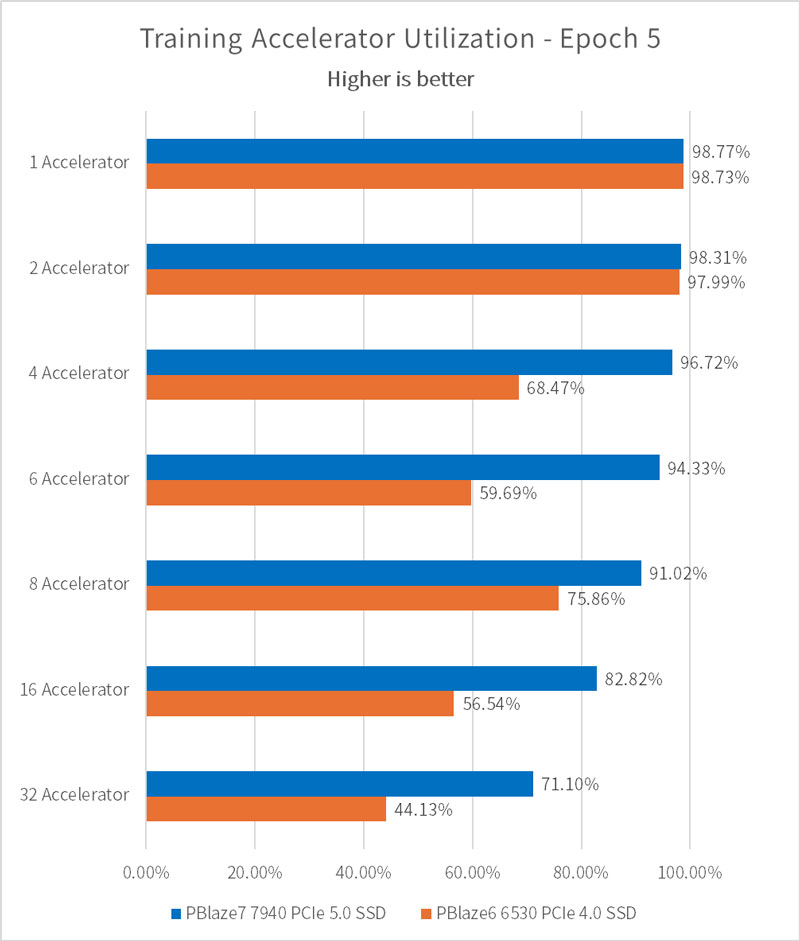
值得一提的是,尽管我们的测试仅使用了一片 PBlaze7 7940 PCIe 5.0 SSD,设定的每一个加速器对 I/O 性能的要求都很高,它仍然可以在8颗加速器的前提下,保证加速器的使用频率维持在 90% 以上!
此外,我们还补充了 epoch = 1 时的 I/O 性能结果,此时,没有任何样本数据可以在缓存中再次命中,SSD 带来的 I/O 性能影响也将被进一步放大。
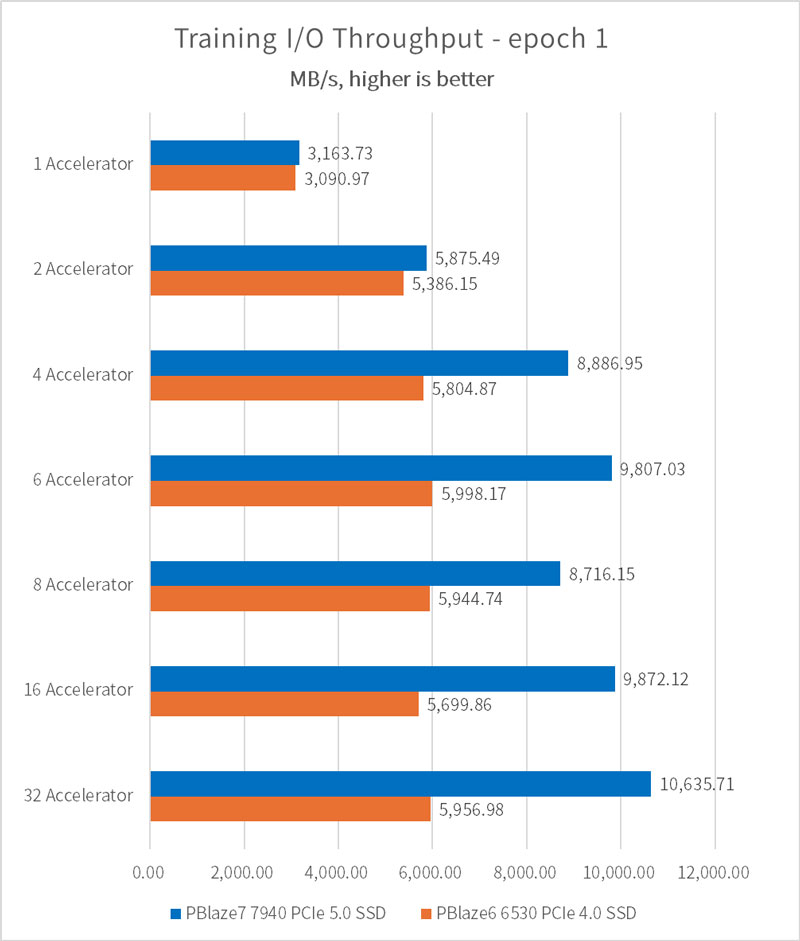
相比较5个 epoch 的设定,此时 I/O 性能仅出现细微下滑,I/O 传输带宽仍然可以达到 10.63GB/s。
使用 iostat 工具可以观察每个训练过程中 SSD 的 I/O 情况。在样本数据加载阶段,SSD 几乎可以达到满速运行。
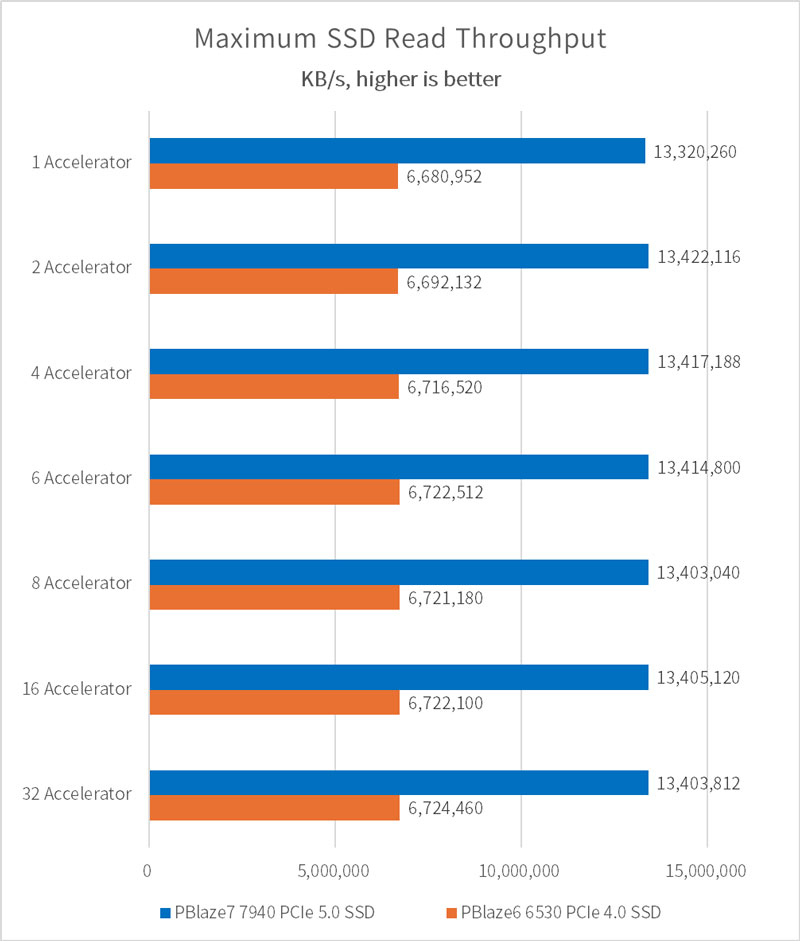
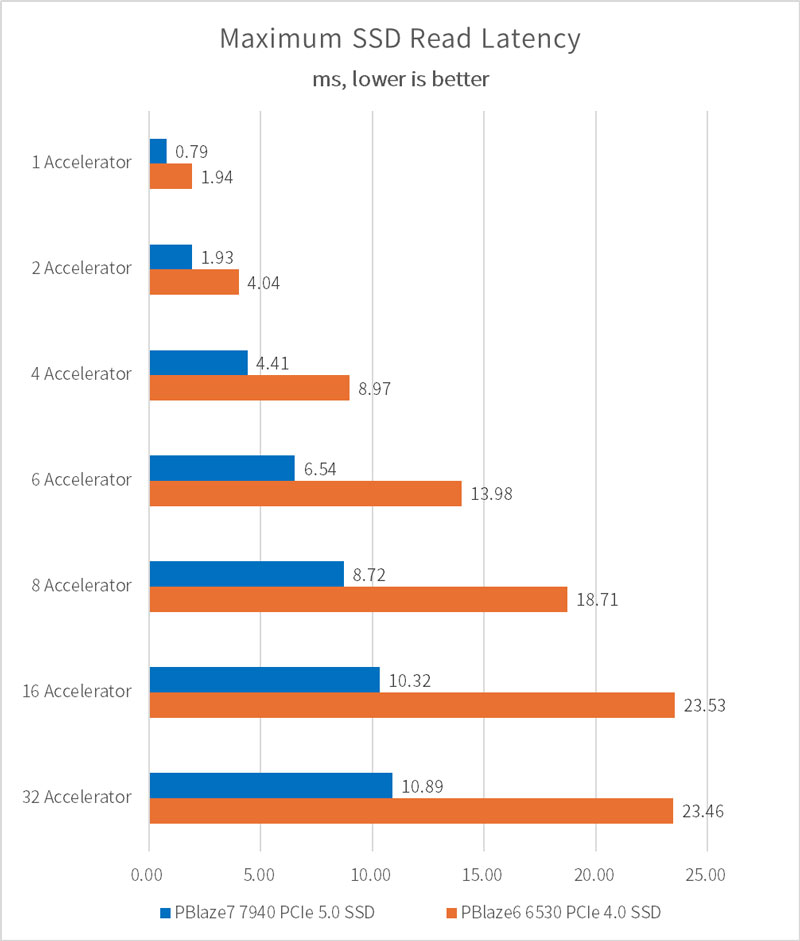
SSD 读延迟如下所示,在近乎满载的情况下,PBlaze7 7940 PCIe 5.0 SSD 延迟相较于 PCIe 4.0 SSD,低了50%以上!
全文总结:
在 AI 训练硬件架构的精密布局中,确保每一个环节都不成为性能瓶颈,是实现高效 AI 训练的核心要义。NVMe SSD 以其极低的延迟、高吞吐量和卓越的读写性能,为 AI 训练过程中的海量数据读写需求提供了强有力的支撑,成为加速 AI 训练进程的重要一环。
而随着 AI 模型规模和复杂度的不断提升,对于计算资源和存储容量的需求也随之剧增。在这样的背景下,拥有更强单片性能的企业级 PCIe 5.0 NVMe SSD 显得尤为关键,它不仅能够提供更大的存储容量,以容纳日益庞大的数据集和模型参数,更能在高负载下保持稳定的高性能输出,为复杂模型、大模型的训练提供持久而强大的支持。
可以预见,随着技术的不断进步和成本的逐步降低,在未来 AI 硬件生态中,NVMe SSD 将扮演越来越重要的角色,成为推动 AI 训练效率革命的重要力量,并促使系统架构师和开发者在构建 AI 训练平台时,更加注重存储系统的优化与升级,以确保整个硬件架构能够充分发挥出每一环节的潜力。
作为国内技术实力领先的企业级 NVMe SSD 厂商,忆恒创源也将不断打磨其技术,不断推出有着更高性能、更大容量、更高能效比的 NVMe SSD 产品,为推动人工智能技术的快速发展和广泛应用持续贡献力量!