
在 AI 领域,模型训练已被证实是用于 AI 实现的有效方法。它广泛应用于宇宙学、物理学、计算机视觉、核聚变、医疗等领域研究,因其算法依赖于大数据量和多样性来有效进行训练任务,因此,I/O 性能是制约模型训练效率的一个重要瓶颈。
GPU 作为整个人工智能训练任务的算力核心,因其成本高昂,系统架构和参数设置应以最大发挥 GPU 的使用效率为目标。同时,模型参数不断增大,数据爆炸式增加,算力需求正得到前所未有的增长,并对底层 SSD、网卡等 I/O 设备提出了更高要求。
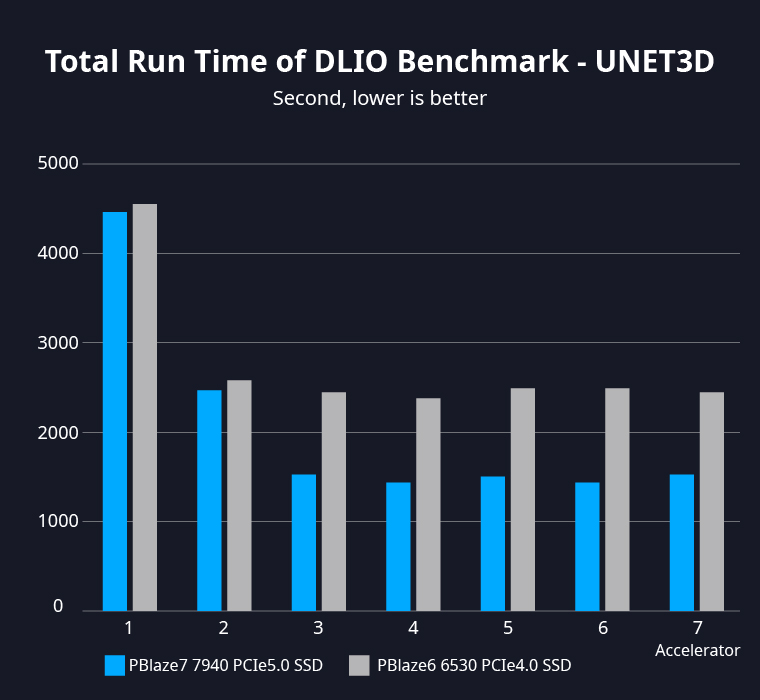
使用 DLIO Benchmark 深度学习 I/O 性能测试工具,在 Unet3D 模型训练测试中加载3TB训练数据,单片 PBlaze7 7940 PCIe 5.0 SSD 可以在5个epoch下节省近1,000秒的时间。
相较于PCIe 4.0 SSD,PBlaze7 7940 在测试中节省了42.6%的耗时,有助于训练任务更快完成。
典型 AI 训练任务需要经过数十个甚至上百个epoch,大量时间被节省下来,可进行更多训练任务,相同时间内带来更高的效益与回报。
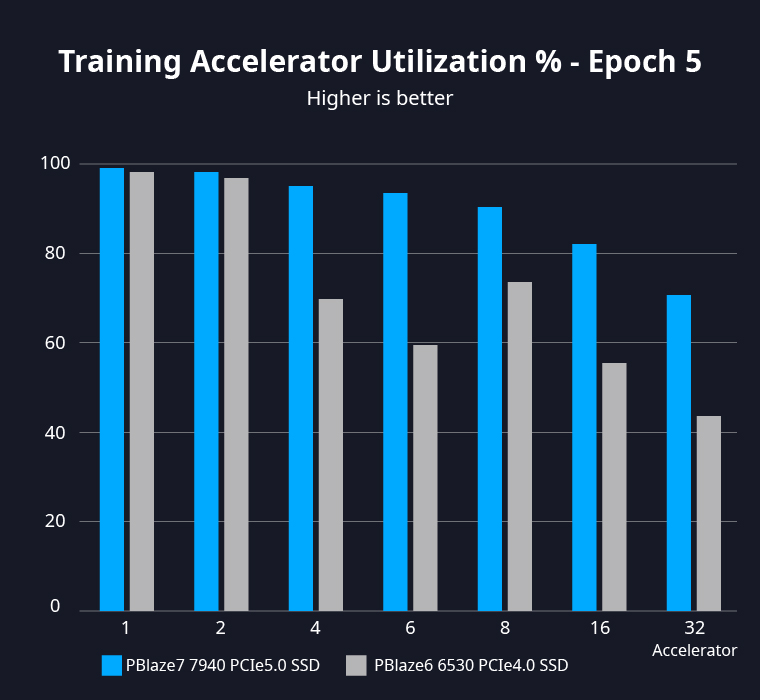
更高的 I/O 性能意味着更短的数据等待时间,让加速器(如 GPU)可以更早开始训练任务。加速器性能越强,训练耗时越短,对 I/O 性能的要求也就越高。
在 Unet3D 训练任务中,通过增加训练数据的读压力,可以获得超过 10GB/s 的 I/O 处理速度,此时选择更高性能的 NVMe SSD 成为必需。
随着加速器数量的增加,每颗加速器获得的数据量被均分,执行效率出现下降。配置单片 PBlaze7 7940 SSD,在模拟训练任务中将8颗加速器的使用效率提高至90%以上。
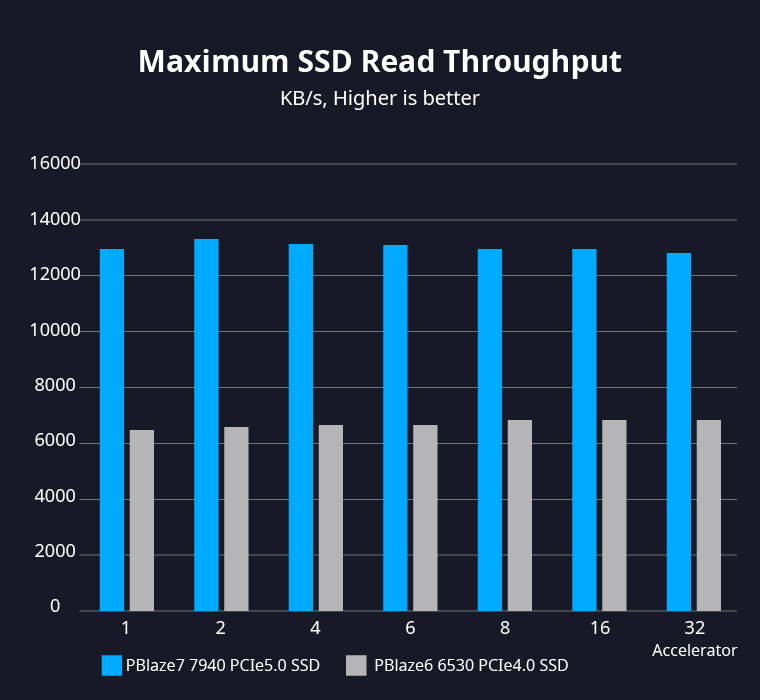
较大的内存容量可以有效减少 NVMe SSD 的读取次数,但也会造成内存成本的大幅增加。选择性能更强的 NVMe SSD,可以在数据样本较大的训练任务中降低内存要求,并减少内存等待数据的时间。
在训练数据加载环节,PBlaze7 7940 SSD 以几乎满载的状态进行数据读取,大幅降低 SSD 读操作带来的性能影响。
在数据集较大的训练任务中,这些数据可能无法全部存储在系统内存当中,通过提高底层 NVMe SSD 性能,可有效减少内存等待数据的时间。
PBlaze7 7940 系列 PCIe 5.0 SSD 可提供两倍于 PCIe 4.0 SSD 的性能与容量密度,可帮助企业客户、AI团队大幅减少 SSD 的部署规模和所需服务器数量,为数据中心带来更高的算力密度并大幅降低 TCO。
提供 14GB/s 顺序读性能和 2800K IOPS 4K 随机读性能,均达到 PCIe 4.0 SSD 两倍。
保持2X读写性能的同时,提供两倍于 PCIe 4.0 SSD 的容量密度,带来存力水平的翻倍提升。
每瓦读性能提升至 970MB/s以上。
相同存力水平下,显著减少所需的服务器、交换机部署数量,可通过配置更多数量的加速器,为算力水平的持续提升打好基础。







