SMART,或者严谨地说:S.M.A.R.T (Self-Monitoring Analysis and Reporting Technology),即“自我监测分析与报告技术”,在硬盘行业耳熟能详。无论是传统的机械硬盘,还是作为后起之秀的固态硬盘,它们都在使用这个技术,让用户可以非常直观的了解手中硬盘的使用情况和健康状态,为故障分析和后续使用带来重要参考。
它的出现可以追溯到1992年,当时,IBM在自己的硬盘上使用类似的故障预警分析技术,并在其他厂商的跟进以及标准化协会的支持下,演变成后来大家熟知的SMART。技术发展到固态硬盘,虽然存储原理不同,但SATA固态硬盘几乎完全沿用了机械硬盘的SMART及其字段定义,也是SATA固态硬盘为了兼容机械硬盘交互设计而做出的重要举措之一。
进入NVMe时代,SMART经过了重新设计,与过去的SMART内容项目有所差别,且厂商之间的信息内容也更加一致和规范,不再各自为政,自行定义。今天的文章不介绍企业级固态硬盘的特有功能,而是和大家详细解读一下,属于NVMe固态硬盘自己的SMART,也方便各位读者通过nvme-cli、AIDA64、CrystalDiskInfo等工具,对自己的硬盘状态有所了解。
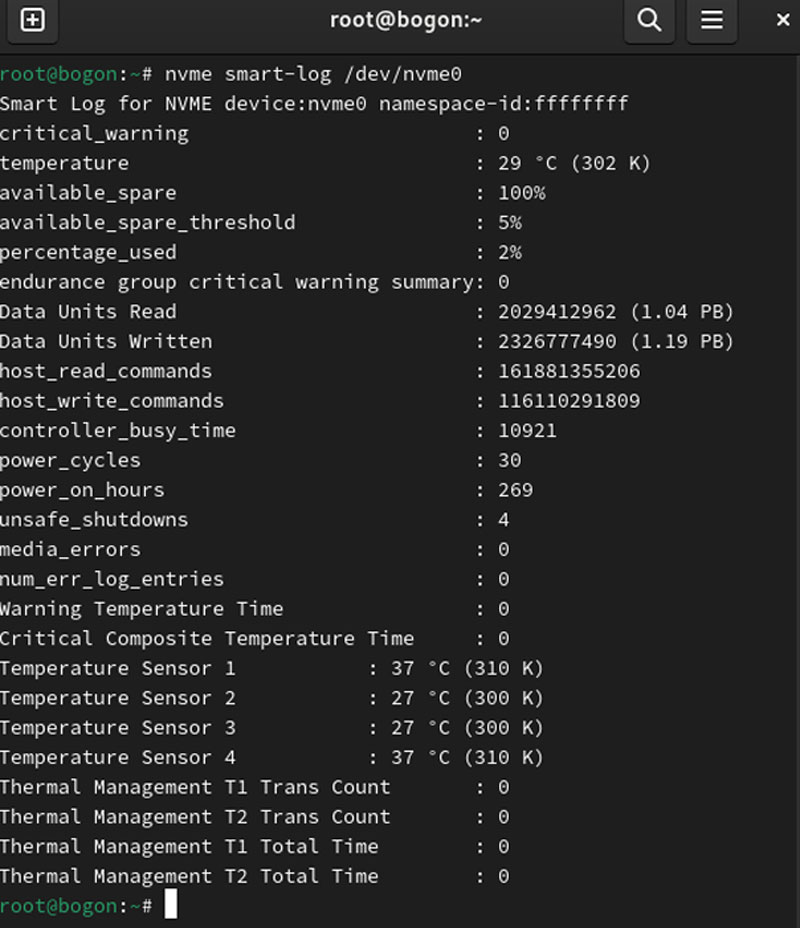
一份典型的NVMe固态硬盘SMART信息
当使用NVMe Admin Command的Get Log Page命令请求Log ID 02h时,你就能得到这份日志(该命令在nvme-cli中为smart-log),此日志页面用于提供SMART和一般健康信息,这些信息涵盖控制器的整个生命周期,且掉电保存。
若要请求基于控制器的此日志页,Host指定的命名空间标识符须为 FFFFFFFFh 或 0h。如若需要提供NVMe 1.4或更早版本NVMe的兼容,Host应使用值为 FFFFFFFFh 的命名空间标识符。根据Identify Controller数据结构中的LPA字段Bit0取值不同,Host也可以被允许获取基于指定命名空间的日志内容。
如果不支持基于命名空间请求该日志页,则可以指定 FFFFFFFFh 或 0h 以外的命名空间标识符终止此命令,状态代码为"Invalid Field in Command (命令存在无效字段)"。假如控制器没有终止此命令,则会返回基于控制器的日志页。
截至目前NVMe 2.0协议规范版本,SMART / Health Information日志页面还没有基于命名空间特别定义的额外字段项,因此基于控制器的日志页面和基于指定命名空间的日志页面包含相同的信息。
有关NVM子系统健康状况的Critical Warning (严重警告)可通过向主机发出异步事件通知来表明。通过Set Feature命令可以具体配置需要产生异步事件通知的警告项。
此外,用户也可以间接通过SMART / Health Information的某些返回参数,来估算出硬盘的负载情况。如,通过读取或写入命令的数量、读取或写入的数据量以及控制器繁忙时间,可以估算出平均每秒 I/O 次数以及带宽。
具体的日志信息如下所示(基于NVMe 2.0协议):
SMART / Health Information Log
Critical Warning (严重警告标志): 该字段用于表明控制器状态的一些严重警告,每个Bit对应一种严重警告类型,允许设置多个Bit为1b值,并可能会向Host产生异步事件通知。
该字段中的Bit只代表当下实时的相关状态,即,当前控制器处于严重警告状态,部分Bit为1b;没有严重警告,或严重警告相应事件结束,对应Bit会被清空为0b。
Composite Temperature (综合温度): 包含一个以开尔文为单位的温度值,代表与该控制器以及控制器关联的命名空间当前的综合温度。这个值的计算方式以具体实现方式为准,并且可能不代表当前NVM子系统中任何物理点位的实际温度值。这个字段的值可用于触发异步事件,如高温保护。
Identify Controller数据结构中的WCTEMP和CCTEMP字段体现了警告和严重过热的综合温度阈值。
以上面的配图为例,Composite Temperature对应“temperature”一行,当前NVMe子系统的综合温度为302开尔文,即29摄氏度。
Available Spare (可用备用容量): 剩余可用备用容量的标准化百分比(0%至100%)。
Available Spare Threshold (可用备用容量阈值): 当可用备用容量降至该字段所指示的阈值以下时,可能会发生异步事件。该值以标准化百分比(0%至100%)表示。数值101至255是保留的。
Percentage Used (已用寿命百分比): 包含基于实际使用情况和制造商对NVM寿命的预测,对NVM子系统已使用寿命百分比的厂商自定义估算。值100表示NVM子系统中NVM的预估耐久度已被使用完,但这可能并不表示NVM子系统故障。该值允许超过100表示,所有超过254的百分比都应表示为255。该值应在NVM通电后每个小时更新一次(当控制器不处于睡眠状态时)。
有关SSD设备寿命和耐久性测量技术,请参考JEDEC JESD218A标准。
Endurance Group Critical Warning Summary (耐久群组的严重警告概要): 此字段表明有关耐久群组的一些严重警告,每个Bit对应一种严重警告类型,允许设置多个Bit为1b值。如果某Bit被清为0b值,则该严重警告类型并没有被触发使用。严重警告可能会向Host产生异步事件通知。此字段中的Bit只代表当下实时的相关状态,并非持久性保留的(即当严重警告相关状态事件结束时就会清空Bit为0b)。
只要在一个或多个耐久群组中有Bit被置为1b,则此字段相应Bit就应该同步置为1b。
Data Units Read (读取单位计数): 以每512个字节为1个单位,主机从控制器读取的数据单位数量。该值在控制器处理用户数据读命令的部分过程中产生,并不包括元数据。
该值以千为单位,并向上取整(例如,值1表示读取的512字节数据单位计数在1到1,000之间,3表示读取的512字节数据单位计数在2,001到3,000之间)。
有关影响此字段的用户数据读取命令列表,请参阅特定的I/O命令集规范。此字段中的0h值表示未报告读取单位计数。
Data Units Written (写入单位计数): 以每512个字节为1个单位,主机向控制器写入的数据单位数量。该值在处理用户数据输出(至硬盘)命令的部分过程中产生,并不包括元数据。
该值以千为单位,并向上取整(例如,值1表示写入的512字节数据单位计数在1到1,000之间,3表示写入的512字节数据单位计数在2,001到3,000之间)。
有关影响此字段的用户数据输出命令列表,请参阅特定的I/O命令集规范。此字段中的0h值表示未报告写入单位计数。
Host Read Commands (主机读命令计数): 包含控制器完成的用户数据读取命令的数量。有关影响此字段的用户数据读取命令列表,请参阅特定的I/O命令集规范。
Host Write Commands (主机写命令计数): 包含控制器完成的用户数据输出(至硬盘)命令的数量。有关影响此字段的用户数据输出命令列表,请参阅特定的I/O命令集规范。
Controller Busy Time (控制器忙状态时间): 包含控制器处理I/O命令的时间。当I/O队列中有未完成的命令时,控制器处于忙碌状态(具体来说,是通过对I/O提交队列尾部门铃进行写入操作,来发出一个命令,并且相应的完成队列实例尚未发布到相关联的I/O完成队列)。该值以分钟为单位报告。
Power Cycles (启动-关闭循环次数): 包含硬盘上电启动到下电关闭的完整循环计数值。
Power On Hours (通电的小时数): 开机小时数,可能不包括控制器通电但处于非运行功率状态的时间。
Unsafe Shutdowns (不安全关机计数): 包含不安全关机的次数。当控制器在主电源丢失之前没有报告可以安全关机时,这个计数会增加。
如果CAP.CPS被清除为00b或设置为01b,在控制器关机流程完成后(即,CSTS.ST被清除为‘0’且CSTS.SHST被设置为10b),就可以安全地关闭控制器电源。
如果CAP.CPS被设置为10b,在NVM子系统关机流程完成后(即,CSTS.ST被设置为‘1’且CSTS.SHST被设置为10b),就可以安全地关闭该域的电源。
如果CAP.CPS被设置为11b,在NVM子系统关机流程完成后(即,CSTS.ST被设置为‘1’且CSTS.SHST被设置为10b),就可以安全地关闭NVM子系统电源。
Media and Data Integrity Errors (介质与数据完整性错误计数): 包含控制器检测到未恢复的数据完整性错误的次数。这个字段包括无法纠正的ECC错误、CRC校验和失败或LBA标签不匹配等错误。
由写入不可纠命令(Write Uncorrectable,参见NVM命令集规范)引入的错误可能也会包含在此字段中。
Number of Error Information Log Entries (错误日志项数): 包含控制器全生命周期中,出现的错误信息日志(LID=01h)计数。
Warning Composite Temperature Time (警告综合温度时间): 包含控制器运行时综合温度大于或等于警告综合温度阈值(WCTEMP)字段,但仍小于严重综合温度阈值(CCTEMP)字段的时间总量(以分钟计),这两个字段位于Identify Controller数据结构内。
如果WCTEMP或CCTEMP字段的值为0h,则无论综合温度值如何,该字段始终清为0h。
Critical Composite Temperature Time (严重综合温度时间): 包含控制器运行时综合温度大于或等于严重综合温度阈值(CCTEMP)字段的时间总量(以分钟计),此字段位于Identify Controller数据结构内。
如果CCTEMP字段的值为0h,则无论综合温度值如何,该字段始终清为0h。
Temperature Sensor 1 (温度传感器1): 包含温度传感器1上报的当前温度值。
Temperature Sensor 2 (温度传感器2): 包含温度传感器2上报的当前温度值。
Temperature Sensor 3 (温度传感器3): 包含温度传感器3上报的当前温度值。
Temperature Sensor 4 (温度传感器4): 包含温度传感器4上报的当前温度值。
Temperature Sensor 5 (温度传感器5): 包含温度传感器5上报的当前温度值。
Temperature Sensor 6 (温度传感器6): 包含温度传感器6上报的当前温度值。
Temperature Sensor 7 (温度传感器7): 包含温度传感器7上报的当前温度值。
Temperature Sensor 8 (温度传感器8): 包含温度传感器8上报的当前温度值。
Thermal Management Temperature 1 Transition Count (热管理温度1转换次数): 包含控制器转换到较低功耗活动状态或执行厂商自定义的热管理行为的次数,这些行为在尽量减少对性能的影响的同时,试图通过主机控制的热管理功能来降低综合温度(即综合温度升高超过热管理温度1)。一旦该计数器的值达到FFFFFFFFh,它不能溢出至0h值。如果该值为0h,表示此转换从未发生过或此字段未使用。
Thermal Management Temperature 2 Transition Count (热管理温度2转换次数): 包含控制器转换到较低功耗活动状态或执行厂商自定义的热管理行为的次数,这些行为不考虑对性能的影响(例如,重度降频),试图通过主机控制的热管理功能来降低综合温度(即综合温度升高超过热管理温度2)。一旦该计数器的值达到FFFFFFFFh,它不能溢出至0h值。如果该值为0h,表示此转换从未发生过或此字段未使用。
Total Time For Thermal Management Temperature 1 (热管理温度1总时间): 包含控制器转换到较低功耗活动状态或执行厂商自定义的热管理行为的总秒数,这些行为在尽量减少对性能的影响的同时,试图通过主机控制的热管理功能来降低综合温度。一旦该计数器的值达到FFFFFFFFh,它不能溢出至0h值。如果该值为0h,表示此转换从未发生过或此字段未使用。
Total Time For Thermal Management Temperature 2 (热管理温度2总时间): 包含控制器转换到较低功耗活动状态或执行厂商自定义的热管理行为的总秒数,这些行为不考虑对性能的影响(例如,重度降频),试图通过主机控制的热管理功能来降低综合温度。一旦该计数器的值达到FFFFFFFFh,它不能溢出至0h值。如果该值为0h,表示此转换从未发生过或此字段未使用。
Temperature Sensor Temperature (TST) (温度传感器温度值): 包含由温度传感器报告的当前温度,单位为开尔文。
NVM子系统中温度传感器报告温度的物理点位以及温度精度是基于实际实现情况的。不使用温度传感器的实现将报告一个值为0h的温度。温度传感器报告的温度可用于触发异步事件。
这里之所以特别强调Windows操作系统,是因为考虑本文面向每一名NVMe固态硬盘的用户,而不仅仅局限在企业级市场。配合具体示例,大家都可以有一个参照,可以在必要时查看自己的硬盘健康状态。如大名鼎鼎的CrystalDiskInfo、AIDA64,以及一些固态硬盘厂商自己打造的专用软件,都可以很直观的看到固态硬盘的SMART信息。
在此,我使用CrystalDiskInfo软件截取了办公电脑中M.2 NVMe固态硬盘的SMART:可以看到,它支持NVMe 1.3协议规范,并且工具显示了各种硬盘的基本信息,如固件版本、序列号、接口、传输模式、分区情况、支持的部分功能等。右边是统计数据,由下方读取的SMART源数据值经过换算得出。这里需要注意,软件中的GB、TB均为二进制下的容量单位,为了严谨,下面统一使用GiB、TiB代替。
如,主机总计读取 10120GB,对应读取的512字节单位计数 21223319,预估的总读取量为 512B * 21223319 * 1000 / 1024 / 1024 / 1024,即 10120GiB。
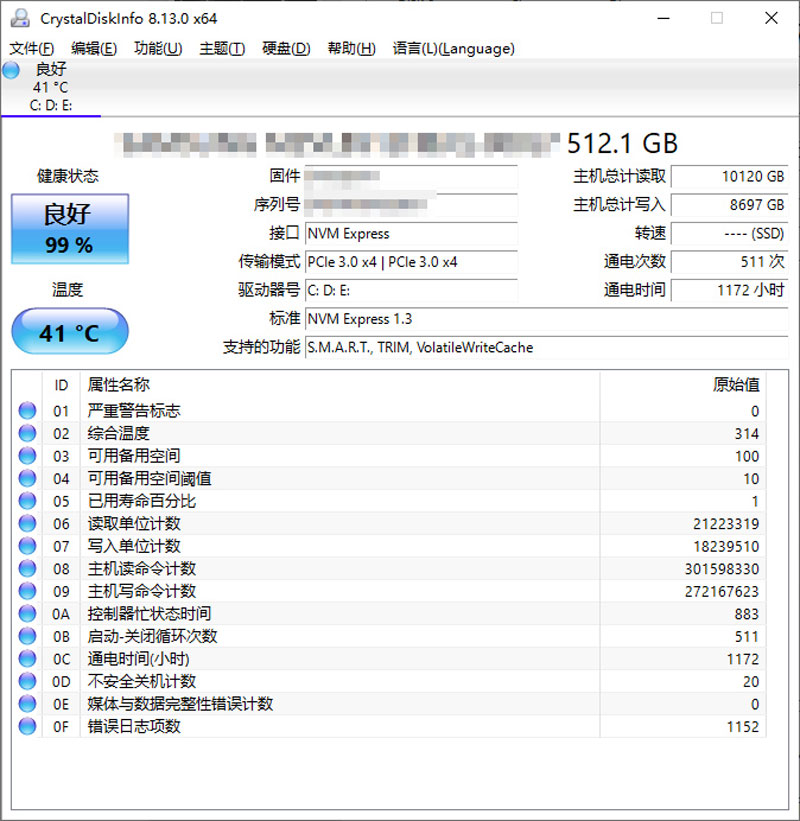
大家应该注意到了,该软件显示的SMART值和我们前面表格里描述的项目几乎一一对应,个别SMART项目没有被列出,如Endurance Group Critical Warning Summary (耐久群组的严重警告概要)、Warning Composite Temperature Time (警告综合温度时间)等。
切换到AIDA64软件,可以看到相同的SMART结果,部分项目名称虽有不同,但数值完全一样。此外,在CrystalDiskInfo中没有显示的Warning Composite Temperature Time和两颗传感器数据也被读了出来。
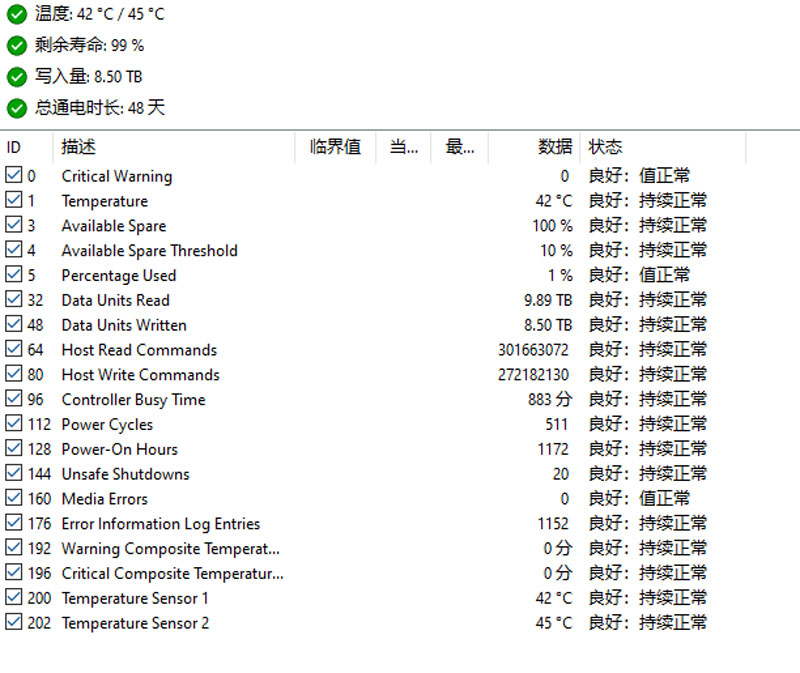
除了主机总计写入量,
01、03、05、0E这几个重要信息外,通过0A,也就是控制器忙状态时间,可以判断固态硬盘的平均负载压力和该硬盘的使用场景是否相符。还是以上图为例,总计读写量18817GiB除以883分钟,得到平均读写带宽为363.7MiB/s,和典型的Office办公场景相符合;如果是图1中2.22PiB的读写总量配合10921分钟的控制器忙时间,则平均读写带宽为3.57GiB/s,和该固态硬盘“性能测试用途”的身份相符合。
以上是围绕NVMe固态硬盘SMART的一些知识点、常见故障计数说明,以及需要我们特别留意的地方,希望能够对大家有所帮助。