大家评判 SSD 的标准,最直观的,就是读写性能了。如我们常谈到的随机性能、顺序性能,前者反映了 SSD 在处理散乱小文件时的应对能力,后者则反映了 SSD 处理单一大文件时的读写速度,也是很多测试软件突出的性能指标。预读是影响 SSD 顺序读性能的重要因素,今天我们就来谈谈这个功能。
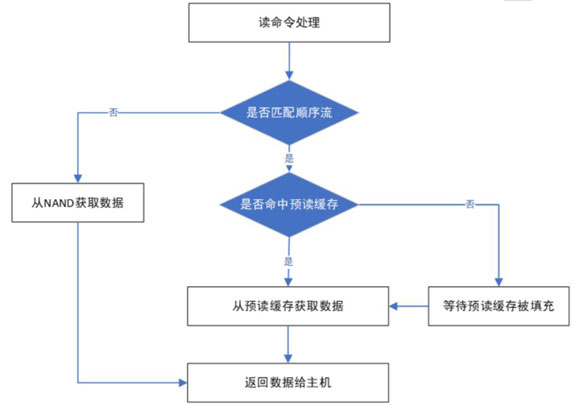
预读,顾名思义,就是通过预测下一个可能读取的 LBA,提前将这些数据准备好,当读请求到来时,SSD 便能做出迅速响应,将数据直接发送给用户,从而大幅缩短响应时间。如果不具备预读功能,SSD 就需要在收到读命令后,再去 NAND 中读取相应数据,这无疑会耗费更多的时间。通常情况下,NAND 读取也是整个读命令处理过程比较耗时的环节。
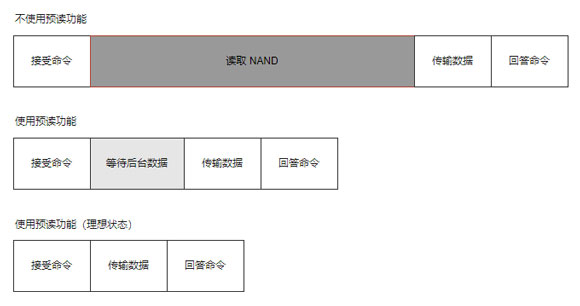
下图为 PBlaze7 7940 SSD 在 Intel 13代酷睿平台的实测结果,测试项目为 4K QD1 的顺序读,在没有启动预读功能时,其延迟为 56.95μs,开启预读功能后,实测整个读命令完成仅需 5.96μs。这一惊人提升,正是预读功能带来的改善。
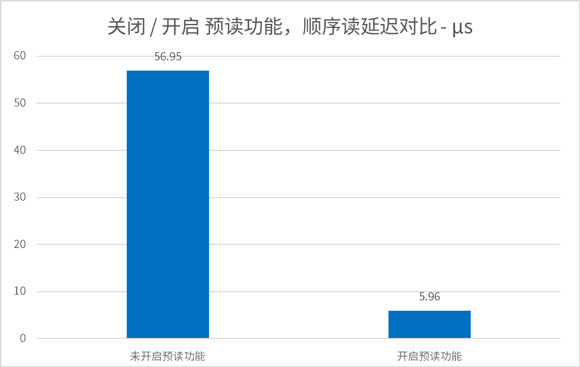
开启预读功能后,4K QD1 顺序读延迟降低至 5.96μs
那么,如何才能将预读功能更好发挥呢?其中关键,在于提高后台效率和预测的成功率。
为提高后台的执行效率,我们不仅可以预测单独的读命令,也可以对下一批命令进行预测。通过将多个命令聚合在一起进行读取,可以有效增加后台读取的带宽,进而缩短每个读命令等待后台数据的时间。此外,由于 SSD 的物理特性,一批连续的读命令,在 NAND 上的分布不一定是连续的,因此我们可以巧妙地合并这些不相邻的命令,以实现更大的并发量。
对于简单的单一顺序流,两个相邻的读命令 A1 和 A2,A1 的起始位置加长度,即末尾,就等于 A2 的起始位置,以此类推,我们可以轻松地预测出整个流程。
然而在现实世界中,顺序流往往会被打乱,或者夹杂着其它随机流或顺序流。因此,我们需要建立一个上下文环境,记录当前顺序流的状态。只有当用户的请求符合这个顺序流的特点时,我们才从该顺序流中读取数据,并推动顺序流的流动。通过这种方法,我们也可以分离出多个顺序流,让顺序读性能得到进一步提升。
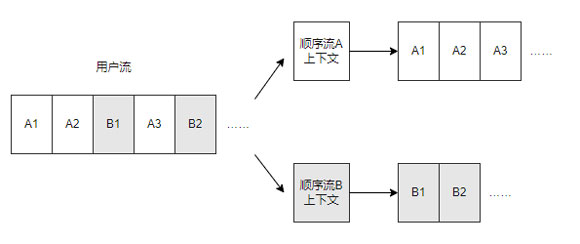
当然,预读功能不能被无限制使用。它在带来更强顺序读性能的同时,也会造成主控、缓存资源的一定占用。为避免对其它同步进行的 IO 命令造成影响,我们会将预读功能约束在一定范围,确保所有 IO 请求都能够得到及时响应。
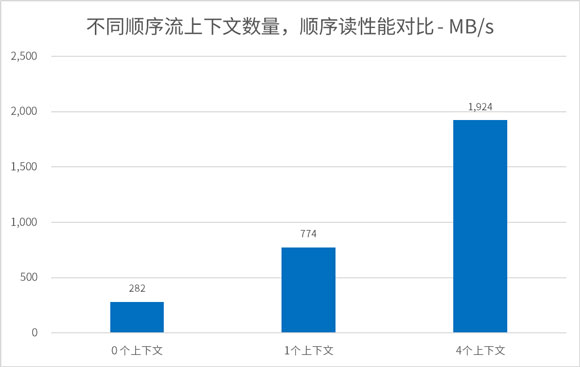
PBlaze7 7940 可以支持多路顺序流,为用户提供了更加灵活和更具效率的读取方式。下图为用户发送4个顺序流的时候,PBlaze7 7940 使用0个顺序流上下文(即不使用预读功能)、1个顺序流上下文,以及4个顺序流上下文的性能表现。可以看到,使用多个顺序流上下文后,SSD 的读带宽得到显著提升,可以更好的应对复杂的用户场景。
在科技的道路上,我们始终倾听客户的声音,致力于提供超越期待的产品体验。PBlaze7 7940 SSD 的预读功能正是源于对客户需求的聆听与追求。我们希望通过这一创新,让 SSD 的读写性能再上一个新的台阶。未来,我们将继续以客户为中心,不断探索、创新,为客户带来更加优异的产品和服务。