日前,全球权威AI基准性能测评组织MLCommons公布了MLPerf v1.0存储性能测试结果:采用忆恒创源PBlaze7系列PCIe 5.0企业级NVMe SSD的焱融F9000X全闪分布式一体机产品凭借极高的IO性能,在带宽、模拟GPU数量、GPU利用率等诸多AI训练关键性能指标方面,均能够保持领先,斩获多项性能第一!
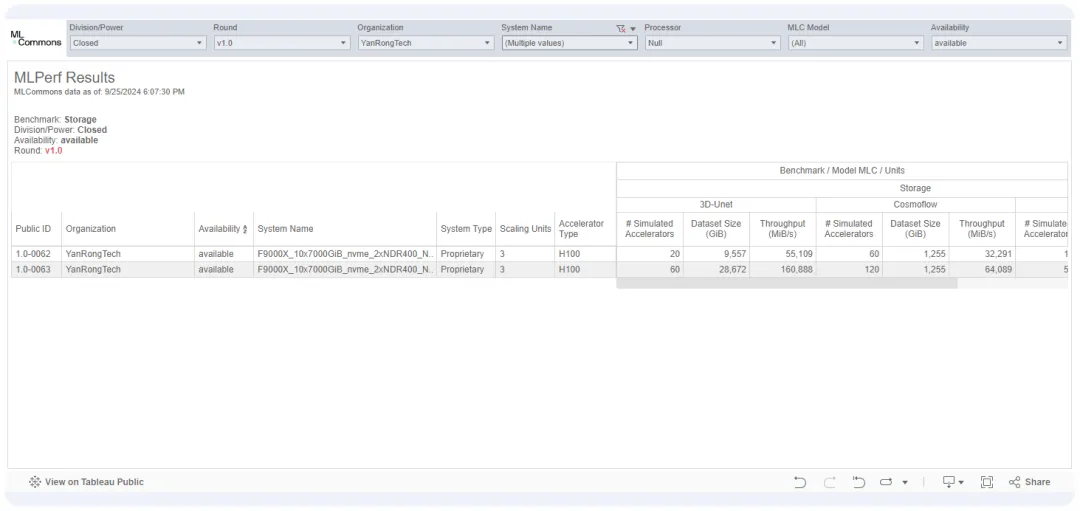
MLPerf Storage测试结果(引自MLCommons网站)
焱融科技是国内一家专注于软件定义存储技术研发的高新技术企业。其自主研发的高性能分布式文件存储产品YRCloudFile在全球IO500性能测试中跻身世界前六,同时也是国内首个进入CNCF Landscape的云原生存储品牌。凭借出色的性能和可靠性,焱融科技正在为国内多家人工智能、智算、自动驾驶、互联网、金融量化、智能制造、能源等行业标杆客户提供服务。
F9000X是焱融科技面向大模型等AI技术应用打造的高性能全闪分布式一体机产品,采用Intel第五代至强可扩展处理器,支持PCIe 5.0高速接口和NVIDIA ConnectX-7智能网卡以完美适配GPU算力集群。存储方面,本次测试使用的F9000X配置了10片由忆恒创源提供的PBlaze7系列PCIe 5.0企业级NVMe SSD,配合焱融YRCloudFile高性能分布式文件系统以实现SSD性能的最大发挥。
MLPerf v1.0由图灵奖得主大卫·帕特森(David Patterson)联合谷歌、斯坦福大学、哈佛大学等学术机构共同发起,旨在快速评估存储系统在ML/AI工作负载中的性能表现,为开发者选择或优化存储方案提供准确参考。
它支持多种具有代表性的训练模型,如3D-Unet、ResNet-50、CosmoFlow等。为了让测试结果具备可比较性与可参考性,测试开始前需要禁用主机节点缓存,以消除缓存的训练数据带来性能影响;同时,测试使用的数据集需远大于主机节点内存容量;此外,为了评估存储性能是否达标,MLPerf v1.0还要求3D-Unet和ResNet-50模型测试的ACC(如GPU)利用率需维持在90%以上,CosmoFlow则为70%以上!
还不熟悉AI训练的小伙伴,也可以参考我们之前发表的文章《实测!高性能 PCIe 5.0 SSD 为AI训练贡献了啥?》里面对模型训练任务中的IO性能测试逻辑、训练模型,以及ACC加速器、AU加速器使用率等重要概念进行了详细介绍,在此不做过多赘述。
在典型ML机器学习训练任务中,存储单元需要以最快的速度将加速器所需的训练样本数据传输至计算节点的系统内存或专用高速缓存,以保证加速器的使用率,确保训练任务及早完成并实现硬件资产回报的最大化。算力水平越高,对存储性能的需求也就越高。
本次测试使用的网络拓扑如下图所示,模拟的ACC型号为NVIDIA H100。根据MLCommons介绍,相较于A100,H100将3D-UNet工作负载的计算时间缩短了76%,此时如果要想继续保持ACC的高利用率,无疑会对存储带宽、延迟提出更加苛刻的要求。
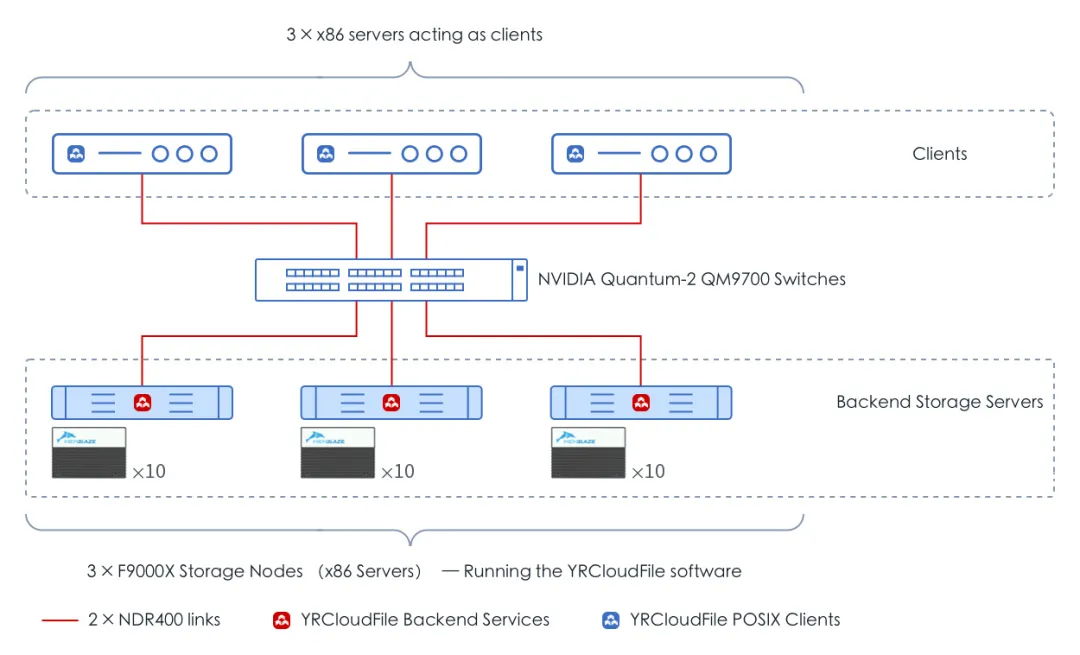
测试时使用的网络拓扑(引自焱融科技)
MLPerf v1.0基准测试不仅支持单个计算节点运行多个ACC,同时也支持大规模分布式训练集群场景,由多个计算节点并发访问存储集群。在保证AU的基础上,平均每个计算节点支持的ACC越多,使用的存储节点规模越小,存储系统的性能越强。
测试结果显示,在分布式训练集群场景中,采用PBlaze7系列PCIe 5.0 SSD的焱融F9000X在部署数量更少的存储节点与计算节点前提下,所能够支持的ACC总数、总吞吐带宽,以及平均单计算节点ACC数量和存储带宽均大幅领先,在与海外众多知名存储厂商的性能比拼中赢得第一!
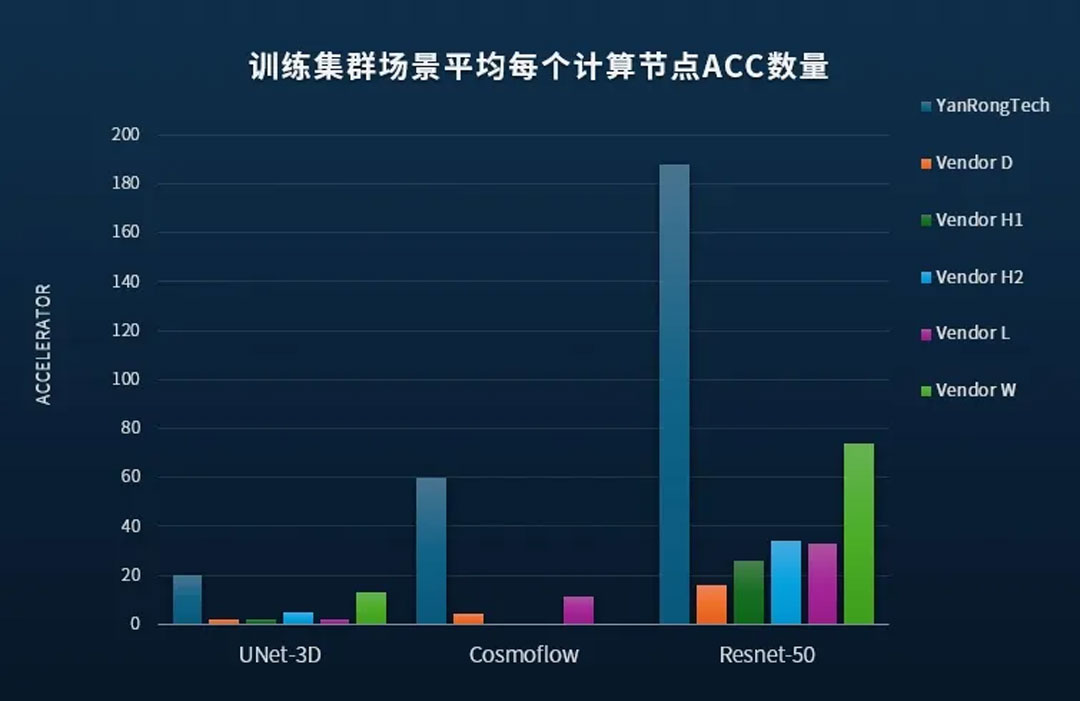
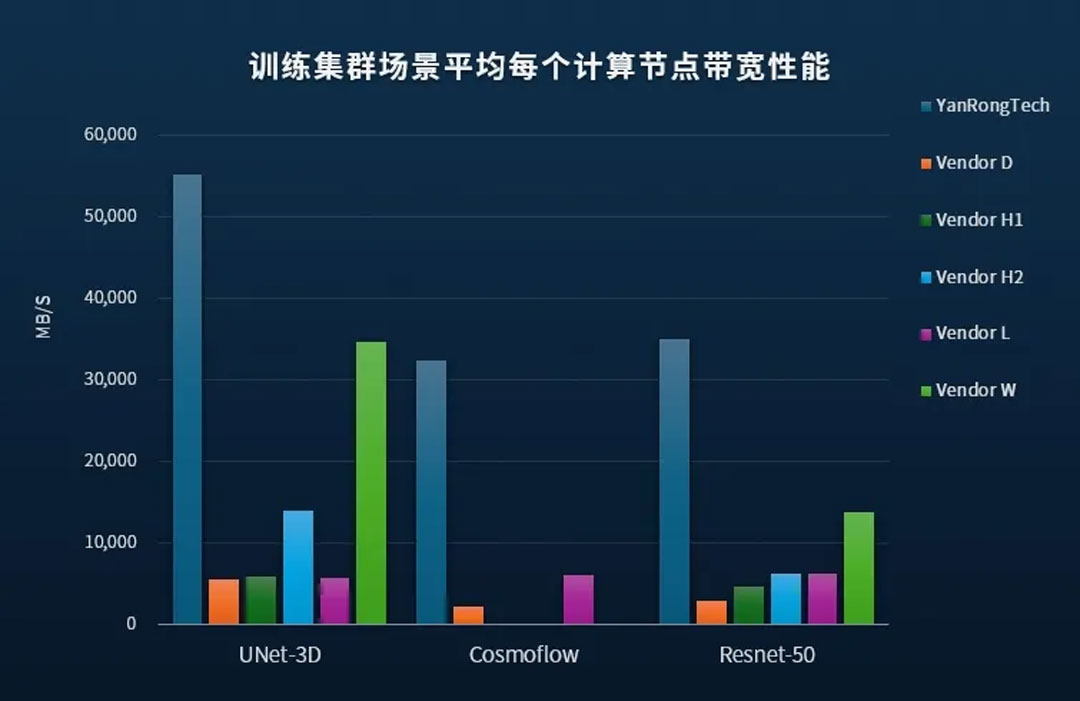
MLPerf v1.0性能比较情况
3D-Unet是业内比较有名的高带宽需求训练模型,其单个图像样本体积约为146MB,在多节点集群环境中,每秒处理样本数量可以超过1100个,训练数据的读取带宽需求将超过160GB/s!
测试中,随着ACC数量的增加,存储集群所提供的带宽也呈现出了明显的线性增长。在配置60个ACC的情况下,3台F9000X存储节点共提供了超过160GB/s的训练样本数据传输带宽,同时AU加速器使用率依然高达96%!根据SSD和IB网卡的实际性能,可以推断此时存储节点依然保留了较高的带宽冗余,也为部署更多ACC,进一步提高训练速度带来根本保障。
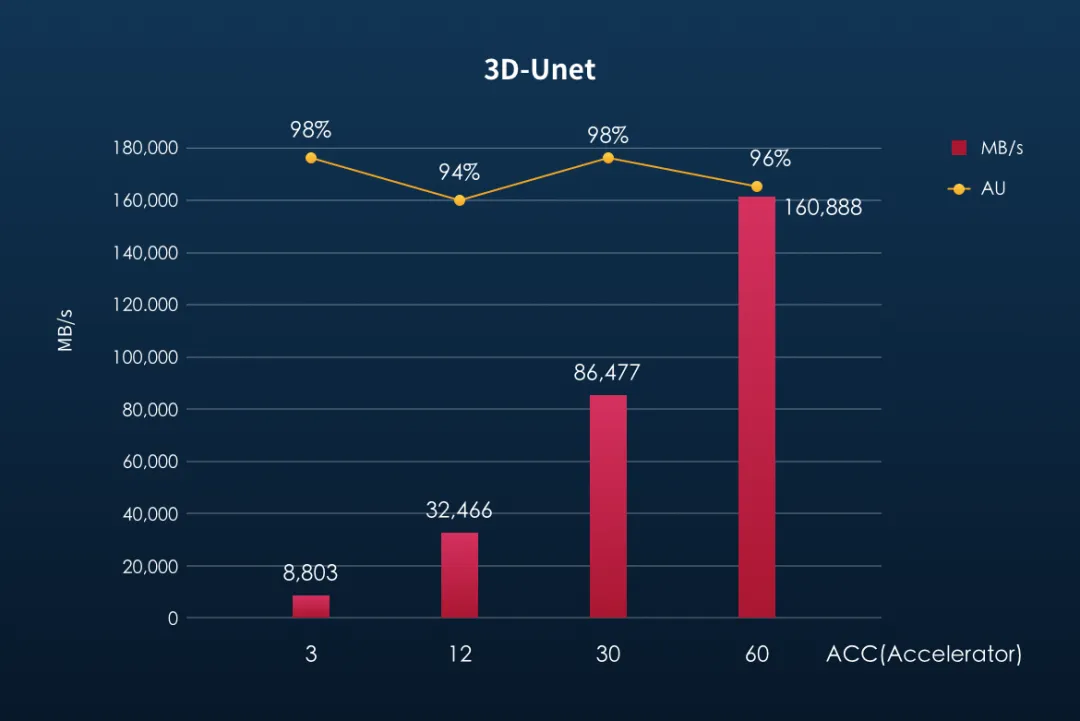
F9000X 3D-Unet性能结果(引自焱融科技)
在ResNet50、CosmoFlow两个模型训练性能测试中,F9000X同样表现优异,前者在保持加速器高达93%使用率的基础上,将ACC数量进一步拓展到540个,后者在保证70%以上加速器使用率的同时,ACC数量也能够支持到120个!
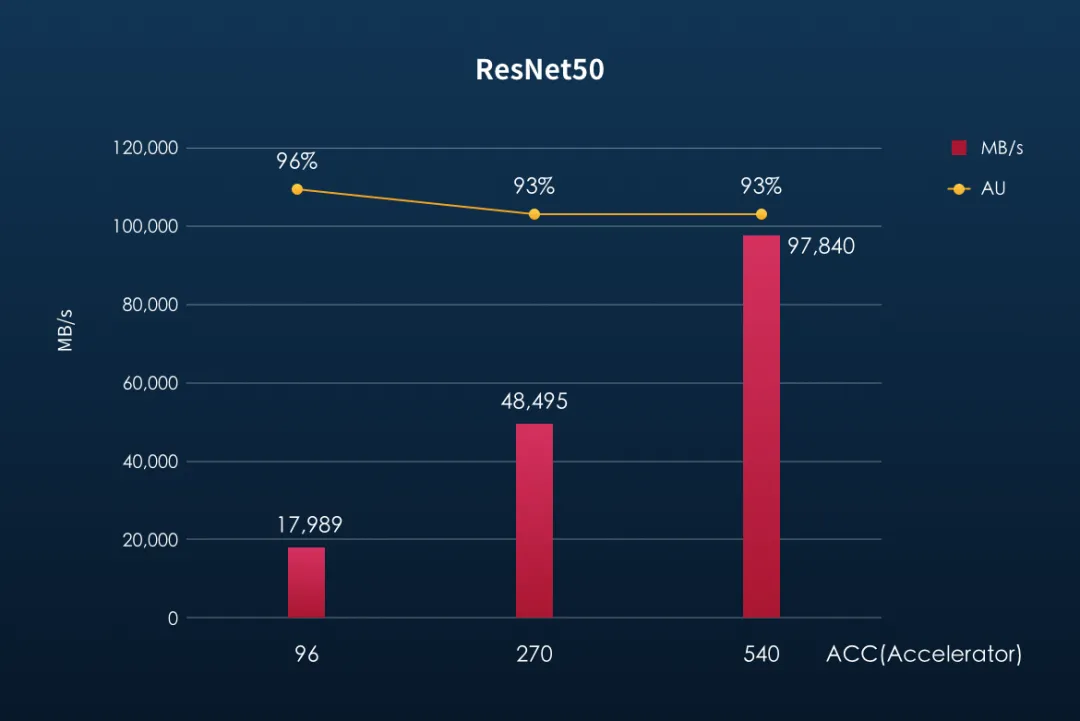
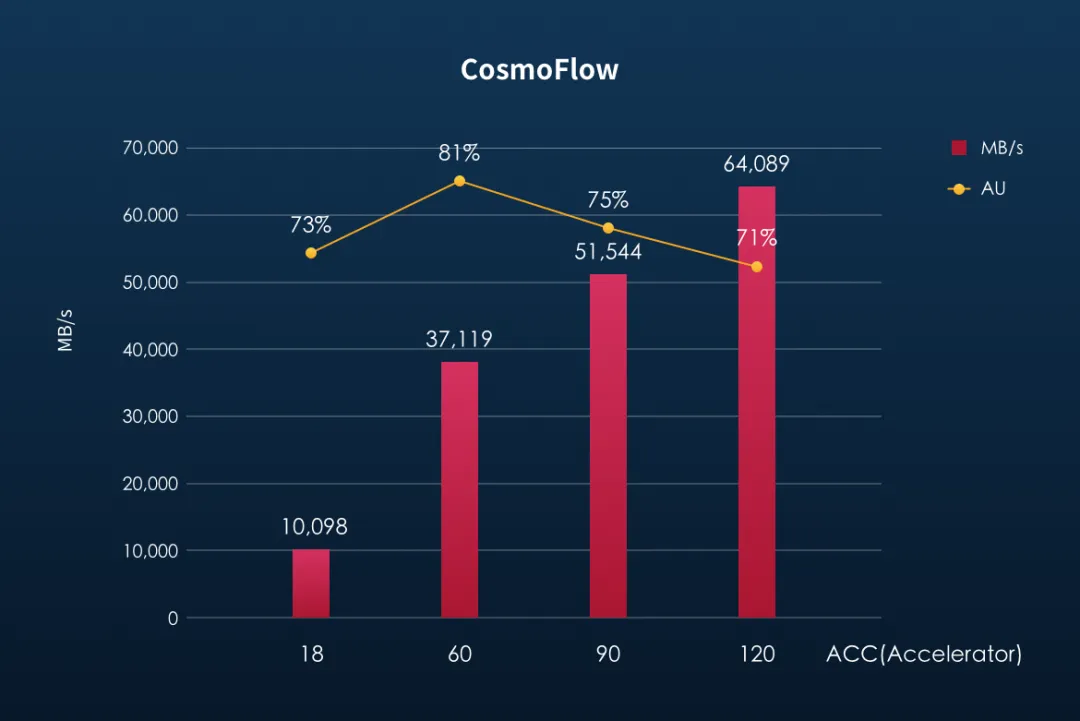
ResNet-50和CosmoFlow性能结果(引自焱融科技)
本次MLPerf v1.0 IO性能测试基本可以看作我们此前DLIO Benchmark的“兄弟”版本,二者的测试逻辑和测试结果不谋而合。作为底层存储介质,PBlaze7系列PCIe 5.0 SSD自身更高的顺序与随机性能、更低的延迟,配合客户专为AI设计的高速文件系统,为整个模型训练任务带来了IO性能的巨大飞跃;存算分离的架构设计,也使得存储单元与计算节点性能均得到更大程度发挥,CPU、内存性能带来的影响被极大消除,即使是配置性能更强的GPU,也能保证更高的GPU使用率,带来训练效率的进一步提升,也为训练集群的横向性能扩展带来保证。
可以说,在AI应用中,性能的需求没有边界,算力、存力、运力,相辅相成。作为技术领先的闪存存储产品供应商,忆恒创源也将继续专注企业级PCIe SSD技术的持续创新与发展,并与焱融科技等众多优秀的合作伙伴紧密配合,以持续突破产品性能、更高的存储密度、更高的能效比和可靠性,为快速发展的AI应用构筑快速高效的存力基座,为推动AI产业的蓬勃发展持续赋能!


