随着9月份MLCommons公布了MLPerf Storage v1.0测试结果,一场席卷整个存储行业的性能竞赛就此展开。用数据说话,也更加有力地展示了存储对于人工智能的重要价值。
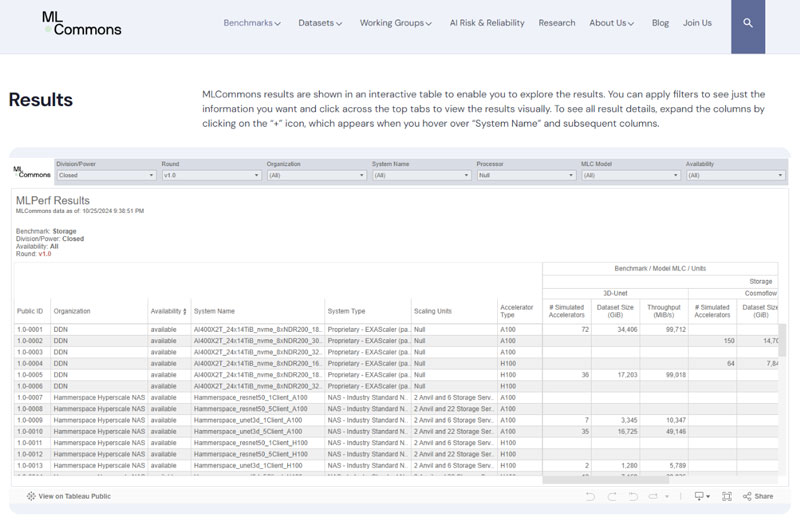
MLPerf Storage页面(引自MLCommons网站)
MLPerf Storage v1.0本质上是此前我们测试过的DLIO Benchmark。DLIO针对多种典型深度学习训练任务制定了快速、科学的IO性能测试方法,通过参数调整,可以模拟不同的GPU,让开发人员能够根据其具体配置进行存储优化,从而提高GPU的使用率。
MLPerf Storage通过更加严谨、统一的参数设置指导,让来自不同厂商、不同硬件配置的测试结果更具参考性与可比较性。DLIO Benchmark的相关介绍、测试逻辑,在前文中有详细介绍,感兴趣的小伙伴可以看这里:《实测!高性能PCIe 5.0 SSD为AI训练贡献了啥?》
这一次,我们基于MLPerf Storage v1.0和默认脚本参数,对我们最新发布的PBlaze7 7A40系列PCIe 5.0 SSD进行完整的IO性能测试。模拟GPU为NVIDIA A100,相较于之前测试使用的V100,A100的运算耗时被缩短了50%以上,对存储性能也就提出了更高的要求。

PBlaze7 7A40系列PCIe 5.0 SSD
测试依旧在此前使用的服务器上进行,配置如下:
测试使用的训练数据集大小为MLPerf Storage v1.0根据平台配置给出的推荐值,测试过程中如遇GPU使用率不达标或其它无法完成测试等情况,则该项测试终止。
最终结果表明,在3个模型训练任务中,PBlaze7 7A40 PCIe 5.0 SSD不论是和友商同类产品的直接性能比对,还是比较多存储节点、多计算节点下GPU的平均带宽,均能够稳列前茅。以下是测试详情:
UNet3D(或3DUNet)是用于医学影像分析的深度学习网络,训练数据的平均体积为146MB,每个文件包含1个样本,Batch Size为7,一次读取的样本数据量约为1GB。脚本中A100 GPU行为耗时0.636秒,因此存储系统需要为每一颗GPU提供近1.6GB/s的数据带宽。根据MLPerf规定,本环节GPU使用率需要达到90%以上。
我们分别模拟了1到8颗A100 GPU的训练过程:
测试结果统计如下,作为对比,MLPerf Storage结果页面某Gen5 SSD单盘性能为9.26GB/s,A100 GPU数量同样为8,PBLaze7 7A40领先幅度达27%!

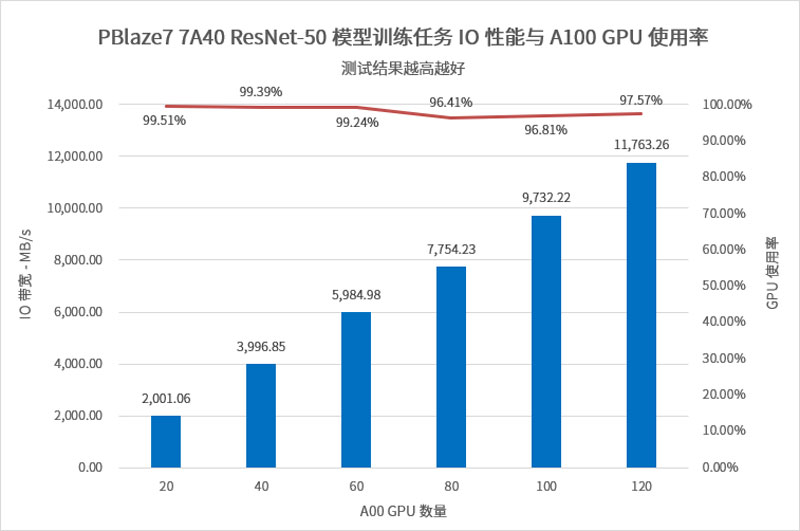
ResNet-50是一种深度残差网络模型,其单个文件体积仅为百余KB,但每个文件包含了高达1251个样本数据,Batch Size是400,属于典型的小文件随机读取,对存储系统的随机响应速度和并发性能会有非常高的要求。本环节GPU使用率同样需要达到90%以上。
我们分别模拟了20到120颗GPU的训练情况,从结果看,即使是单片PBlaze7 7A40 SSD,也能在当前CPU、系统内存配置下,为GPU带来足够充沛的IO性能,在120颗A100 GPU时提供了高达11.76GB/s的数据带宽,GPU的使用率仍然保持在97.57%!
测试结果如下,作为对比,MLPerf Storage官网页面上能够查询到的某Gen5 SSD单盘性能为10.45GB/s,A100 GPU数量为115。
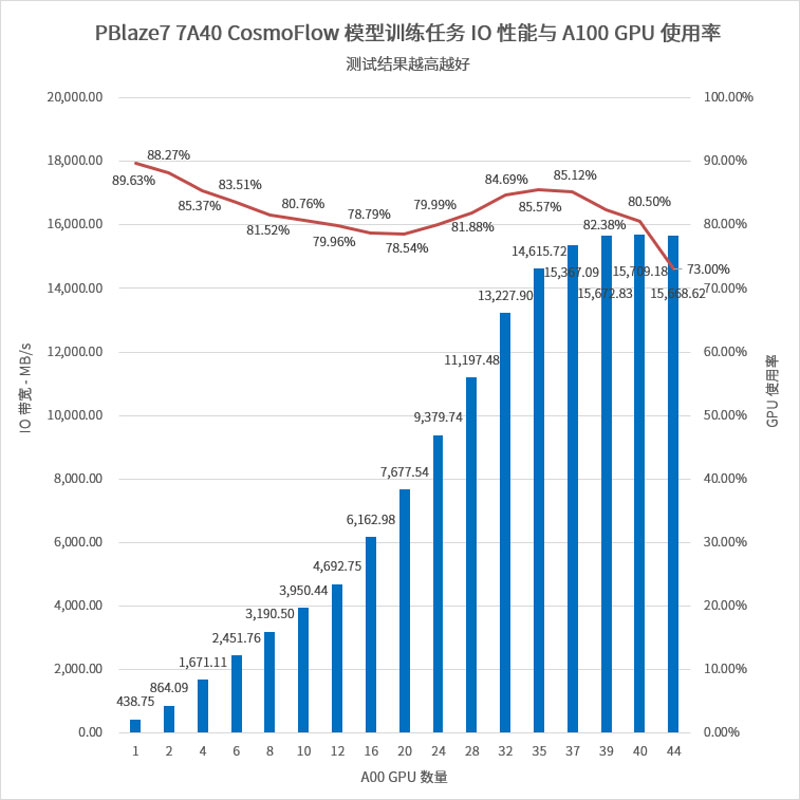
CosmoFlow是用于宇宙探究的深度学习训练框架。测试中使用的样本数据集涵盖971819个样本文件,每个文件体积约为2.8MB,Batch Size为1,GPU行为耗时仅为0.00551秒,对SSD随机读取大文件的响应速度有非常高的要求。根据测试要求,本环节GPU使用率需要达到70%以上。
我们分别模拟了1到44颗A100 GPU的CosmoFlow模型训练过程:
测试结果统计如下,作为对比,MLPerf Storage官网页面上能够查询到的某Gen5 SSD单盘性能为7064MB/s,对应A100 GPU数量为20颗。
受限于平台性能以及时间等因素,本次测试并没有模拟NVIDIA H100 GPU,一些更加极端的测试用例也被迫中止。但尽管如此,PBlaze7 7A40 PCIe 5.0 SSD在模拟A100 GPU的三个模型训练任务中,均发挥出色,不管是和友商同类产品的直接性能比对,还是比较多存储节点、多计算节点下A100 GPU分得的平均带宽,PBlaze7 7A40都能稳列前茅。
正如前文所说,在典型AI训练任务中,确保每一个环节都不会成为性能瓶颈,是实现高效AI训练的核心要义。这里不光有GPU,有HBM,有CPU,有高性能网卡,高性能NVMe SSD同样必不可少,只有这样,方可在源头上确保足够高的IO性能,为高效训练任务带来最最基础的保障。


