Random read/write and sequential read/write speeds are two of the most fundamental metrics for evaluating SSD performance. The former reflects the SSD's ability to handle scattered small files, while the latter shows how well it processes large, continuous files. A key factor that significantly influences sequential read performance is the read-ahead feature—which we'll explore in detail today.

As the name suggests, read-ahead refers to the process of predicting the next Logical Block Address (LBA) that may be requested and proactively preparing the corresponding data. When the actual read command arrives, the SSD can immediately respond by sending the data directly to the host, significantly reducing latency. Without read-ahead, the SSD must retrieve data from the NAND flash only after receiving the command — a process in which NAND access is typically the most time-consuming step.
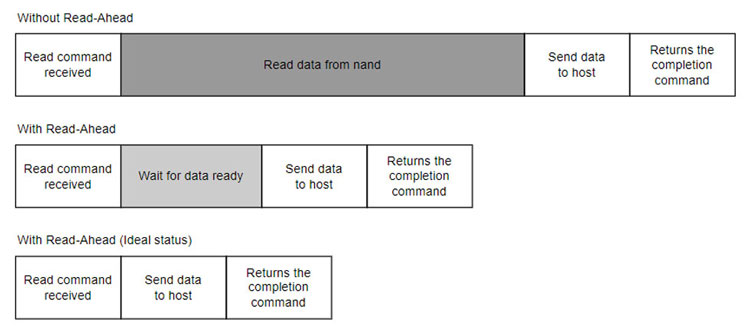
The chart below shows test results for the PBlaze7 7940 SSD on a 13th Gen Intel Core platform, measuring 4K QD1 sequential reads. With read-ahead disabled, latency was 56.95μs. Once read-ahead was enabled, the read command completed in just 5.96μs. This dramatic improvement highlights the power of the read-ahead feature.

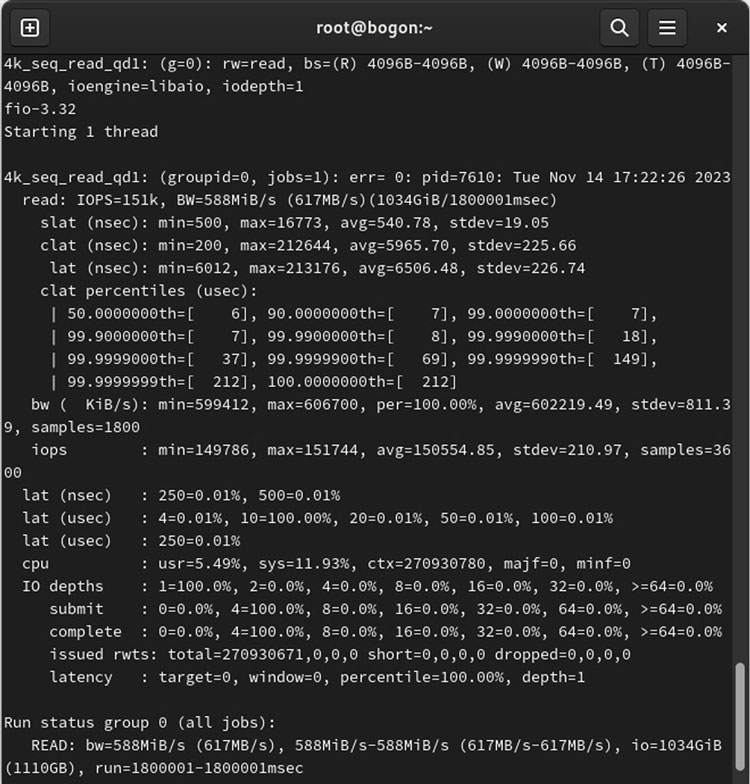
Latency drops to 5.96μs for 4K QD1 sequential read after enabling read-ahead
To fully capitalize on the advantages of read-ahead, it is crucial to enhance both the SSD's backend processing efficiency and the precision of its prediction algorithms.
To improve backend execution efficiency, we not only predict individual read commands but also anticipate upcoming batches of commands. By grouping multiple commands for collective processing, we can significantly increase backend read bandwidth and reduce the wait time for each command to access data. Moreover, due to the physical characteristics of SSDs, data required by a sequence of read commands may not be stored contiguously in NAND. Therefore, intelligently merging these non-contiguous commands enables greater concurrency and overall performance.
For a simple, single sequential stream, two adjacent read commands A1 and A2 can be easily predicted — A2's starting point is simply the end of A1. This pattern allows for accurate and efficient read-ahead.
However, real-world workloads are rarely this clean. Sequential streams are often interrupted or mixed with other random or sequential streams. To handle this, we establish a context environment that tracks the state of ongoing streams. Read-ahead is triggered only when a user's request matches the expected pattern of a stream. This mechanism allows us to manage multiple streams in parallel, further improving sequential read performance.
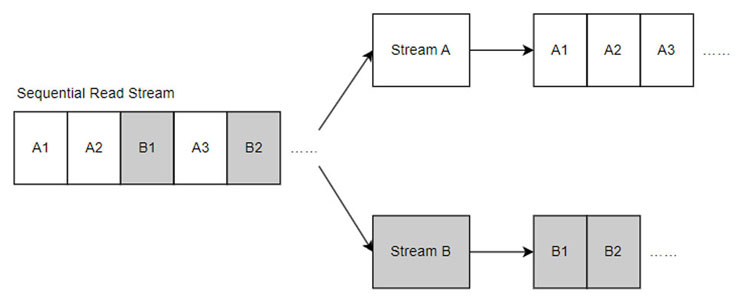
Naturally, read-ahead is not used without limits. While it enhances sequential read performance, it also consumes controller and cache resources. To prevent interference with other ongoing IO operations, we apply constraints to read-ahead to ensure timely responses for all requests.
The PBlaze7 7940 supports multiple sequential streams, giving users a more flexible and efficient way to access data. The chart below shows how the SSD performs when users initiate four sequential streams: with 0 stream contexts (read-ahead off), 1 context, and 4 contexts. With multiple stream contexts enabled, the read bandwidth significantly increases, better handling complex user scenarios.

At Memblaze, we always listen to our customers and strive to deliver a product experience that exceeds expectations. The read-ahead feature of the PBlaze7 7940 SSD is a direct result of this commitment. Through this innovation, we aim to push SSD performance to the next level. Looking ahead, we will continue to focus on our customers, driving innovation to bring them even more outstanding products and services.