In the field of AI, deep learning is an effective method for achieving AI implementation. It is widely used in research areas such as cosmology, physics, computer vision, fusion and healthcare. Since its algorithms rely on massive and diverse sample data, the loading speed becomes a critical factor that restricts the efficiency of model training.
High-cost AI compute chips, like GPUs, require system architectures and training parameters to maximize computational power. As model parameters and data grow exponentially, the demand for computing power increases rapidly, placing higher demands on underlying I/O devices like SSDs.
In deep learning, SSDs typically provide sample data for model training and store intermediate results like checkpoints, logs, and temporary files. This report demonstrates the impact of SSD performance on deep learning using DLIO Benchmark, comparing the PBlaze7 7940 PCIe 5.0 SSD with the PBlaze6 6530 PCIe 4.0 SSD.
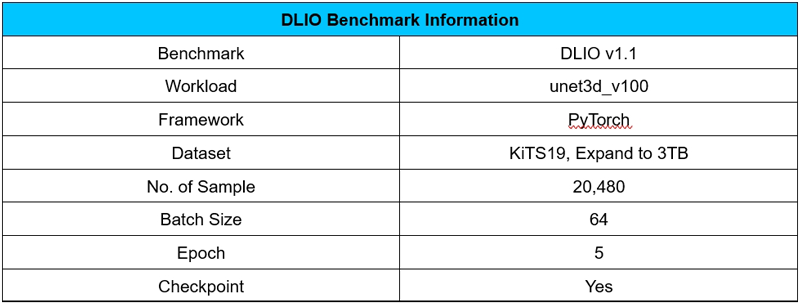
DLIO Benchmark supports frameworks like TensorFlow, PyTorch, offering testing scripts for models like BERT, CosmoFlow, ResNet-50, and Unet3D. By simulating training behavior, it helps developers quickly identify I/O bottlenecks, optimize system architecture, and accelerate the training process.
The Unet3D script, used for medical image analysis, was chosen for this testing. It effectively extracts contours and edges of organs, tissues, and lesions in images, aiding in diagnosis and treatment. Despite having fewer parameters, the model's large average sample size demands high I/O throughput. During the test, the dataset was expanded to 3TB, six times the host memory capacity, with the epoch set to 5.
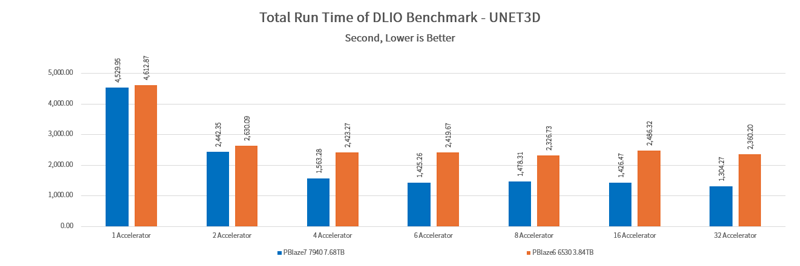
The results show that SSDs can run at full speed during data loading to minimize training performance impact. The PBlaze7 7940 PCIe 5.0 SSD provides significantly better I/O performance, leading by up to 81%. Configuring a more powerful SSD allows more GPUs to operate at higher frequencies, reducing training time by over 40%.
Simulating model training with different GPU configurations using DLIO benchmark, we recorded the test time. This method reflects the tangible benefits of configuring higher performance SSDs in real deep learning workloads.
Data is read from the SSD, sent to memory, and then copied to the GPU's GDDR or HBM. If SSD performance is inadequate, it will become an I/O bottleneck, causing the GPU to wait and extending training time.
In simulations with 1 and 2 GPUs, both the PBlaze7 7940 SSD and the PBlaze6 6530 SSD met the Unet3D training requirements with minimal difference in training time. However, as the number of GPUs increased, the performance advantage of PBlaze7 7940 SSD became evident, significantly reducing training time and achieved a 44.7% reduction in time compared to the PBlaze6 6530 SSD, helping to complete training tasks more quickly.
Deep learning training typically requires dozens or even hundreds of epochs. By saving significant time, more training sessions can be conducted, resulting in greater benefits and returns for the company within the same timeframe.
I/O performance is not only affected by the SSD, but also reflects the bottlenecks in the system architecture. In this test, both SSDs with a single GPU showed excellent I/O performance of 3100MB/s, which is in line with the expected performance of the parameter settings.
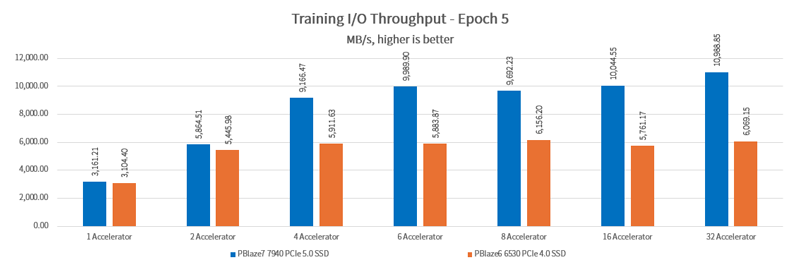
The PBlaze6 6530 SSD significantly enhances I/O performance with 2 GPUs, making it an ideal choice for this configuration. The PBlaze7 7940 SSD, when paired with 4 GPUs, achieves an I/O throughput of 9GB/s. However, as more GPUs are added, the performance gains start to level off. To maintain optimal performance, additional SSDs and upgrades to the CPU and memory are necessary.
When running just 1 epoch, the GPU relies heavily on the SSD for data retrieval, making SSD performance crucial. Both SSDs still deliver excellent I/O performance in this scenario. The PBlaze7 7940 PCIe 5.0 SSD shows a particularly notable advantage with more GPUs, achieving a maximum I/O throughput of 10.6GB/s.
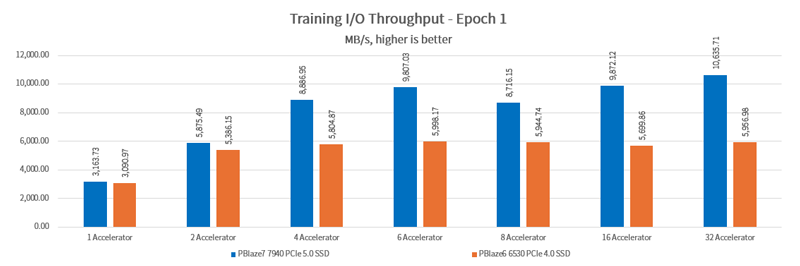
Sample processing speed is affected by many factors such as SSD performance, CPU performance, memory capacity, GPU configuration, etc., the result is the same as I/O throughput.
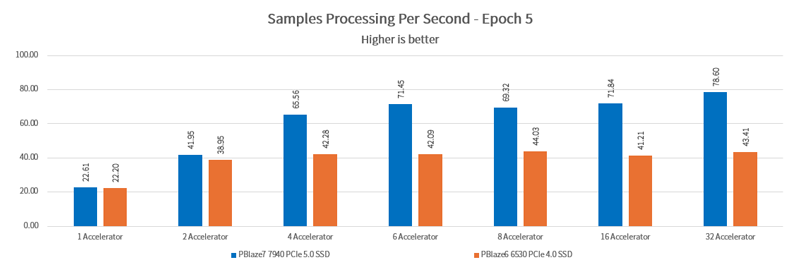
In deep learning applications, GPU utilization is a critical measure of whether the hardware architecture and parameter settings are reasonable. As the number of GPUs increases, I/O demand rises linearly. However, if the storage architecture's maximum I/O performance is exceeded, GPU utilization will decrease, resulting in unnecessary waste.
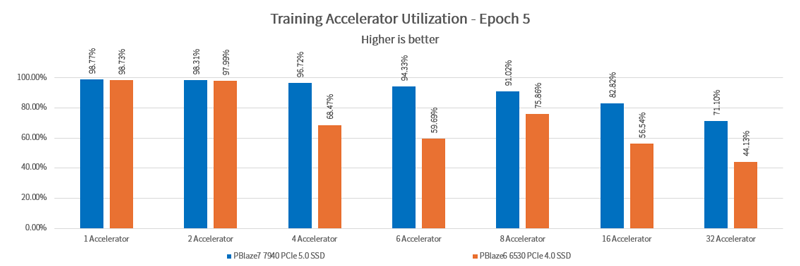
The PBlaze6 6530 PCIe 4.0 SSD can deliver nearly 98% utilization for 2 GPUs in the I/O-intensive Unet3D test. Meanwhile, the higher-performance PBlaze7 7940 PCIe 5.0 SSD can increase the utilization of 8 GPUs to over 90%.
During the data loading phase, running the SSD at full speed ensures that data is quickly transferred to system memory for GPU use. Higher SSD performance reduces read times, allowing the GPU to begin training tasks sooner.
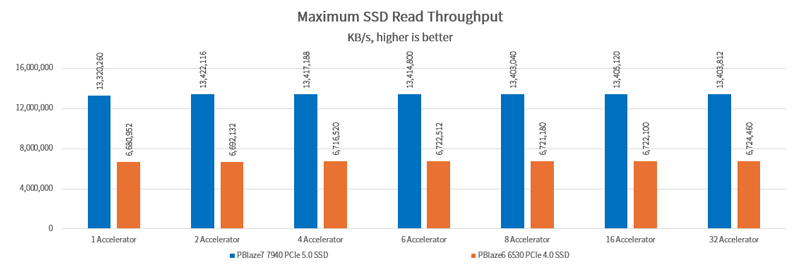
Proper read parameter settings can enable the SSD to operate at maximum performance. With just 1 GPU configured, the PBlaze7 7940 PCIe 5.0 SSD can still achieve read performance exceeding 13GB/s.
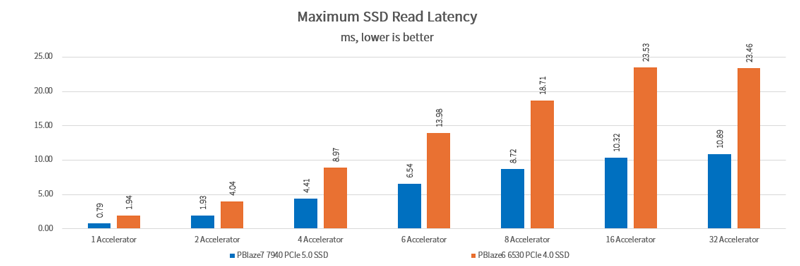
As the number of GPUs increases, the SSD receives more I/O requests per second. Lower latency allows GPUs to access the required data more quickly. The PBlaze7 7940 PCIe 5.0 SSD achieves over 50% lower latency compared to the PBlaze6 6530 PCIe 4.0 SSD.
In the precise design of deep learning hardware architecture, preventing every node from becoming a bottleneck is essential for efficient model training. The rise of AIGC has pushed model training complexity to new heights, dramatically increasing the need for computational resources and storage capacity. In this context, high-performance enterprise PCIe 5.0 SSDs are essential. They provide larger capacities to manage expanding datasets and model parameters while delivering stable, high-performance output under heavy workloads, offering robust and reliable support for training complex and large models.
In the test, the PBlaze7 7940 PCIe 5.0 SSD delivers strong support for massive data read and write requests in deep learning model training. With extremely low latency, high throughput, and excellent read/write performance, it enable multiple GPU configurations to achieve high utilization rates and significantly accelerate the training process.
Higher computational performance demands higher performance from underlying I/O devices. It is foreseeable that with continuous technological advancements and gradual cost reductions, PCIe SSD will play an increasingly important role in the future AI hardware ecosystem, and become a key force driving the revolution in AI training efficiency, prompting system architects and developers to focus more on optimizing and upgrading storage systems when building AI training platforms to ensure that the entire hardware architecture can fully realize its potential.
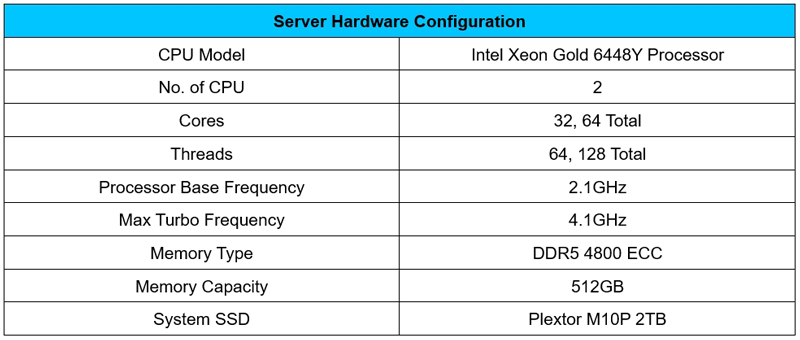
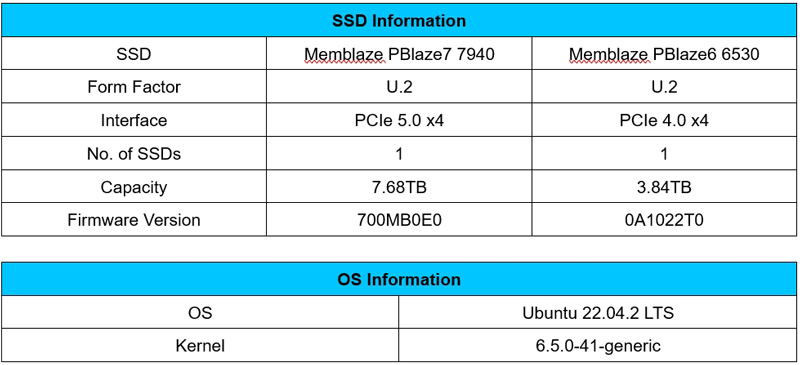
Appendix: Test Environment