今日、AI の普及についてはもはや説明の必要はありません。コンピューティング能力、アルゴリズム、データは、AI テクノロジーの急速な発展を推進するトロイカを構成します。
完全な AI トレーニングには、データ収集、データ前処理、データ・アノテーション、データ・セグメンテーション、モデル設計、モデル構築、モデル・トレーニング、モデル評価、モデル・チューニング、および最終展開が含まれます。 GPU はモデル・トレーニング全体のコンピューティング・コアであるため、システム・アーキテクチャとパラメータ設定は GPU の使用頻度を最大化することを目的としている必要があります。
モデルのトレーニング段階では、SSD は通常、GPU が必要とするサンプル・データを提供し、GPU トレーニングによって生成された中間結果、ログ、一時ファイルなどを保存するために使用されます。データ量が爆発的に増加するにつれ、効率的なデータの取り込みと処理が大きな課題になります。 SSD がモデル・トレーニングに及ぼす影響を調査するために、この記事では DLIO ベンチマーク・テスト・ソフトウェアを使用して検証します。
この記事は長いため、読みやすいように結論を以下に示します:
以下にテストの詳細を記載します。
DLIO Benchmark は、ディープ・ラーニング・アプリケーションの負荷に関する業界で非常に有名な I/O パフォーマンス・テスト・ツールです。これは、開発者がトレーニング・プロセス中に I/O 動作をシミュレートすることで、システム・アーキテクチャ内の I/O ボトルネックを迅速に発見するのに役立ち、トレーニング・パフォーマンスの最適化を導きます。
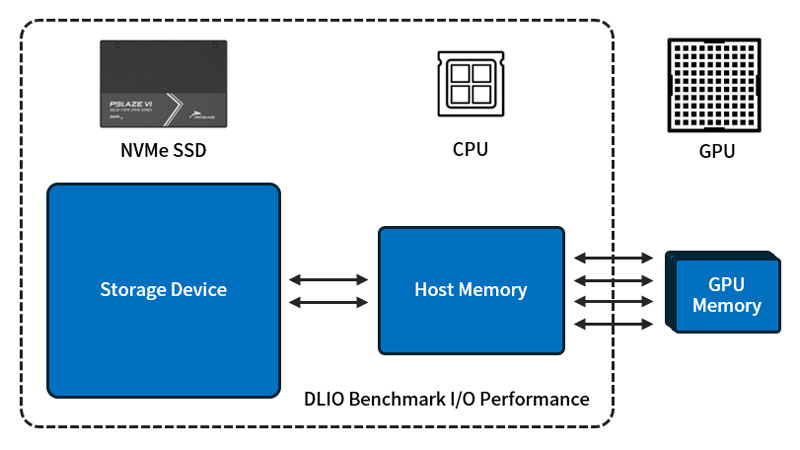
図に示すように、ハードウェア・アーキテクチャでは、ハードディスク、システム・メモリ、GPU にボトルネックがあってはなりません。時期尚早なデータ供給により GPU が待機することになります。GPU のパフォーマンスが低い場合は、それに応じてデータ要求が減少します。
DLIO ベンチマーク テストは、画像分類、自然言語処理、宇宙構造の探索など、さまざまな深層学習モデルのタスクをカバーします。これらのテストを通じて、特定のハードウェア構成と動作パラメータに基づいて、TensorFlow、PyTorch などのさまざまな深層学習フレームワークの特定のタスクでの I/O パフォーマンスを取得できます。
DLIO Benchmark には、次のような複数の標準モデル・トレーニング・タスク・スクリプトが組み込まれています。
テストに使用した環境は以下のとおりです:
このテストでは、UNet3D スクリプトを使用して、20,480 のサンプル・ファイルのトレーニング・ プロセスをシミュレートします。サンプル量は 3TB に達し、システム・メモリをはるかに超えるため、システムはサンプルを複数のバッチに分けてロードします。GPU がデータのバッチを取り出すと、SSD は GPU がこのバッチのトレーニングを完了する前に次のデータのバッチをメモリに書き込む必要があり、これによってSSD の読み取りパフォーマンスをテストできます。
各シミュレーション・トレーニングは 5 エポックにわたって実行され、各エポックの終了時にトレーニング・サンプル・セットが再ロードされ、メモリにキャッシュされた約 500 GB のデータが更新されます。サンプルのロード順序がランダムであるため、少数のサンプルがキャッシュにヒットする可能性があり、その結果、I/O パフォーマンスがわずかに向上します。もちろん、システム・メモリがすべてのサンプル・データを収容できる「十分な大きさ」であれば、I/O パフォーマンスの向上は明らかですが、コストも大幅に増加します。
ここでは、DLIO Benchmark ソフトウェアを使用して、1、2、4、6、8、16、および 32 GPU の構成をそれぞれシミュレートします。
モデルのトレーニング時間
PBlaze7 7940 SSD はテスト時間を 40% 以上節約!
AI モデルのトレーニングとそのデータ読み込み動作をシミュレートすることで、SSD 構成と GPU の数が異なる場合のトレーニング プロセスの時間の違いを計算できます。結果は次のとおりです:
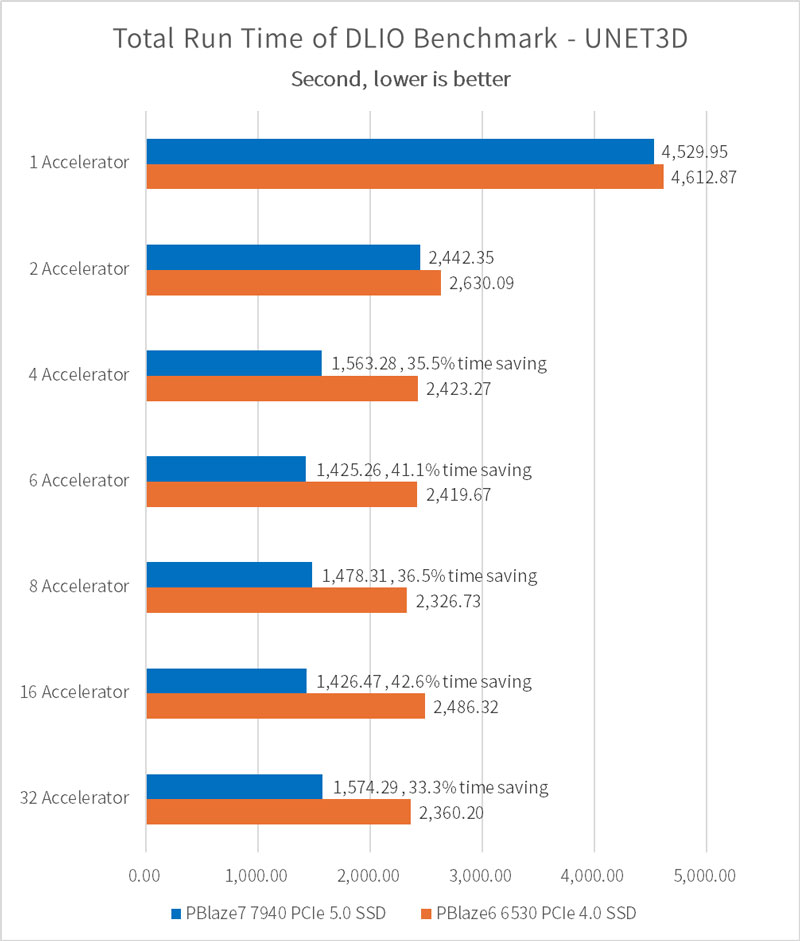
epoch=5 の場合、ひとつの PBlaze7 7940 PCIe 5.0 SSD を構成することで、4 つ以上の GPU を使用したトレーニング・タスクで PCIe 4.0 SSD と比較して 1,000 秒近く節約できます。 80 エポックが完全なトレーニングであると仮定すると、節約される時間は 16,000 秒に達する可能性があり、80回の完全なトレーニングでは 14.8 日節約されます。
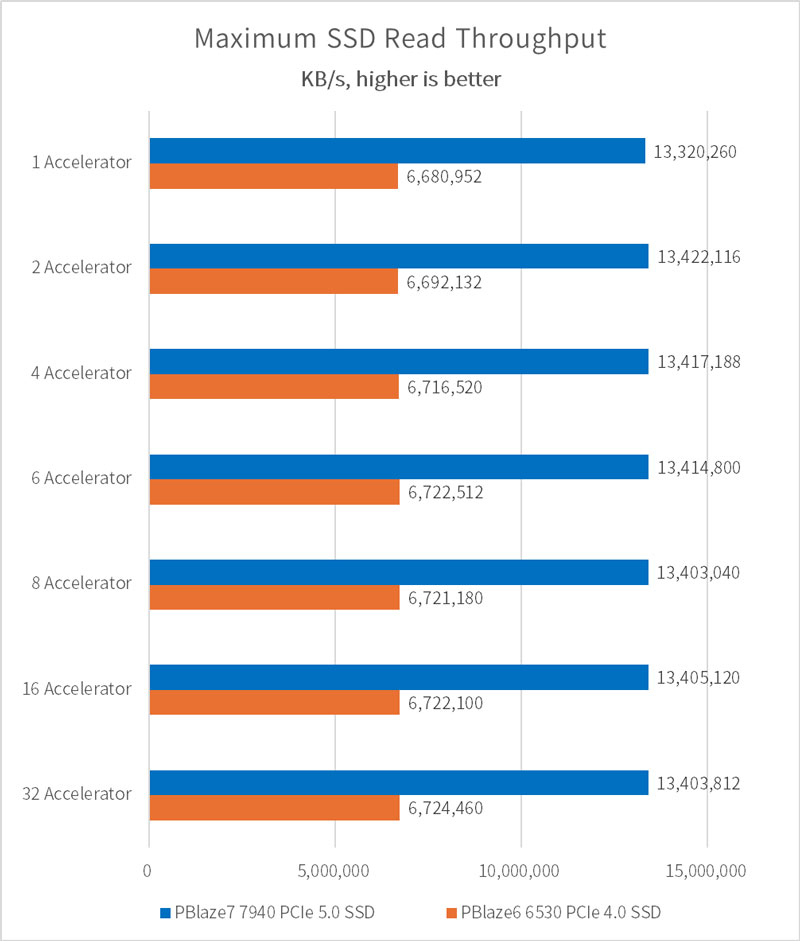
単一アクセラレータでは 3 GB/s を突破、複数アクセラレータでは 10.98 GB/s に達する!
アクセラレータ (GPU) の数が 1 に設定されている場合、PBlaze7 7940 PCIe 5.0 SSD と PBlaze6 6530 PCIe 4.0 SSD で構成されるトレーニング・プラットフォームは、両方とも 3.1GB/秒の I/O パフォーマンスを実現できます。平均サンプル・ファイル・サイズ 146MB、アクセラレータごとに一度にロードされるサンプル数 32、および V100 GPU の計算リンク置換パラメータに基づいて、アクセラレータの理論上の処理限界は 3400MB/s であると結論付けることができます。これは SSD やシステム・メモリの読み取り帯域幅とは程遠いです。したがって、サーバーを増やさずにアクセラレータ (GPU) の数を増やし続け、トレーニングのパフォーマンスを向上し続けることができます。
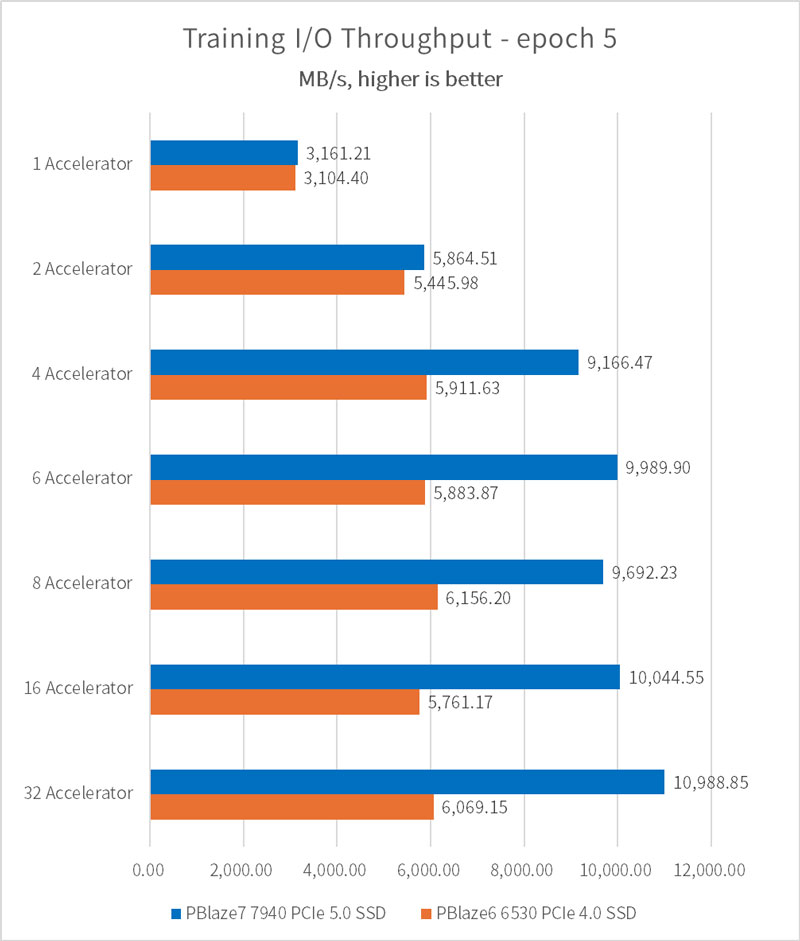
4つのアクセラレータで構成されている場合、PBlaze7 7940 PCIe 5.0 SSD トレーニング・プラットフォームは9.16 GB/秒の I/O パフォーマンスを提供でき、6つのアクセラレータで構成されている場合、CPU とメモリは長時間フルロードされ始めます。 I/Oパフォーマンス向上率も低下し始め、最終的な I/O パフォーマンスは 10.98GB/秒になりました。
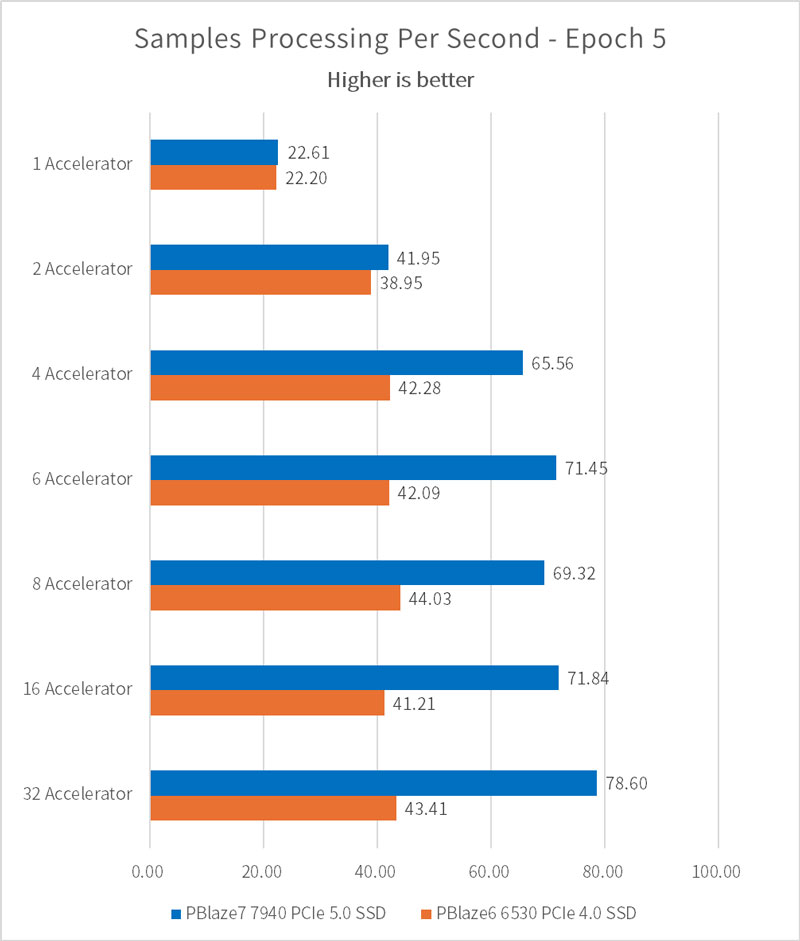
1 秒あたりに処理されるサンプルの数は、I/O パフォーマンス・テストの結果と一致します。値が大きいほど、モデルのトレーニングの速度が高くなります。
ひとつの PBlaze7 7940 で 8 GPU の使用率が 90% に向上
Accelerator Utilizationは、アクセラレータ (GPU) の使用効率を表します。アクセラレータの数が少ない場合、PBlaze7 7940 によって構成されたトレーニング・プラットフォームは、アクセラレータのデータ要求を満たすことができます。このとき、アクセラレータの使用率は 98.77% に達します。アクセラレータの数が多いと、各アクセラレータが獲得できる I/O 転送帯域幅が少なくなり、使用効率も低下します。
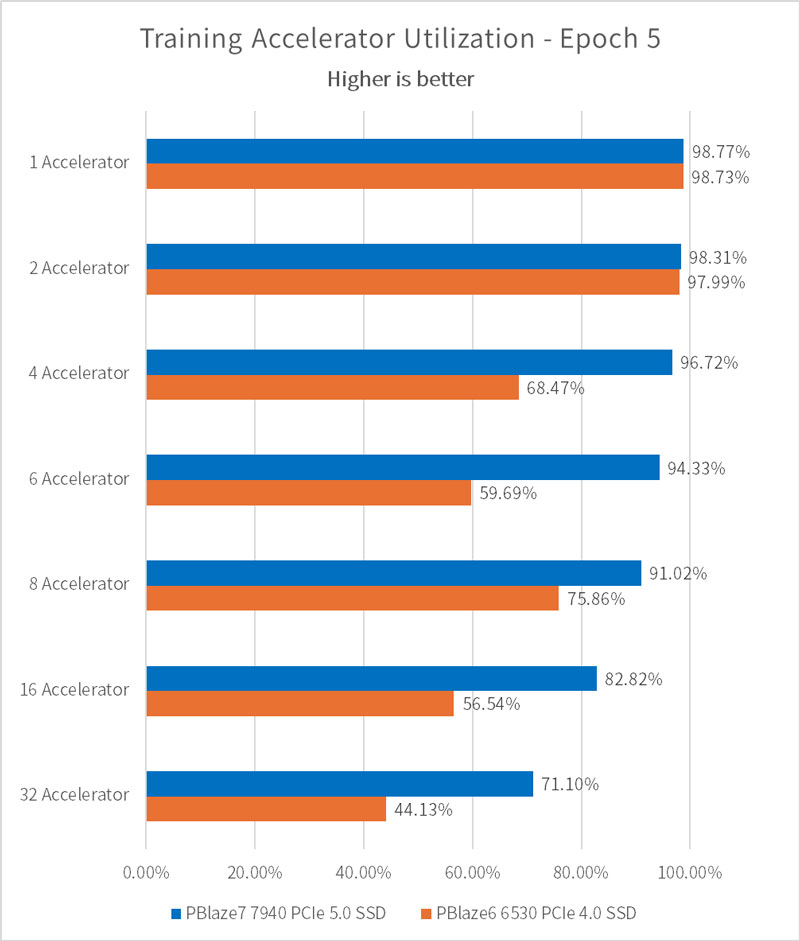
注目すべき点は、テストでは PBlaze7 7940 PCIe 5.0 SSD を 1 つだけ使用し、各アクセラレータ・セットには高い I/O パフォーマンス要件があるにもかかわらず、8 つのアクセラレータの場合でもそれぞれのアクセラレータ使用頻度は 90% 以上を維持できることです。
PBlaze7 7940、PBlaze6 6530の動作は引き続き好調!
さらに、epoch = 1 の場合の I/O パフォーマンスの結果も補足しました。この時点では、キャッシュ内でサンプル・データが再びヒットすることはなく、SSD によってもたらされる I/O パフォーマンスの影響はさらに増幅されます。
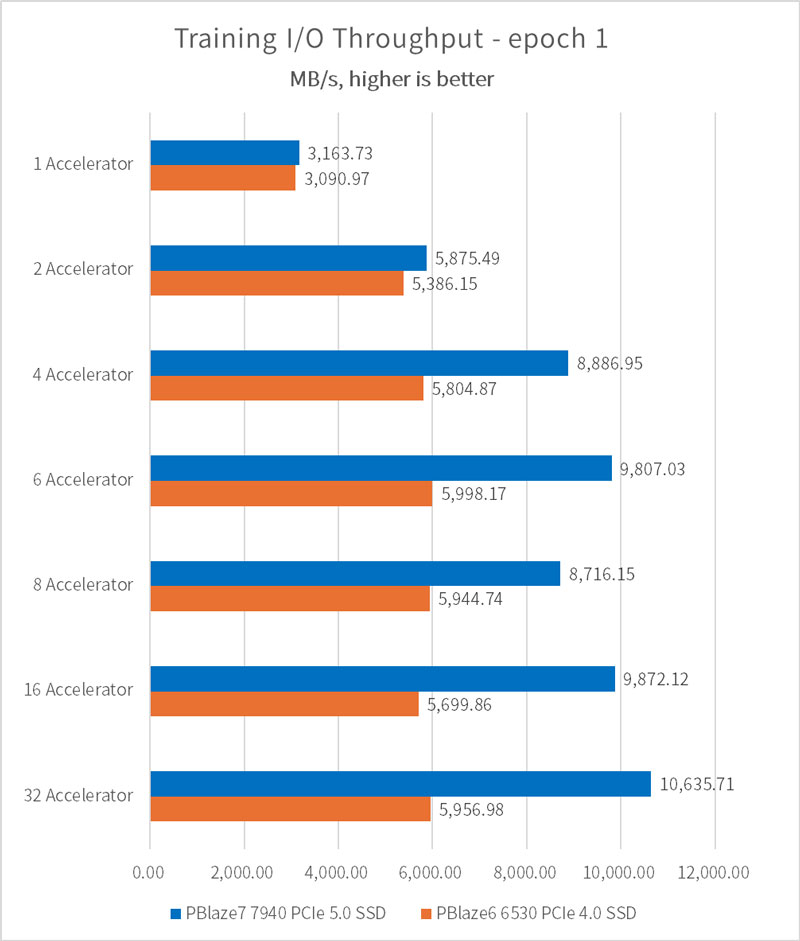
5 エポックの設定と比較すると、現時点では I/O パフォーマンスはわずかな低下を示しているだけで、I/O 伝送帯域幅は依然として 10.63GB/s に達します。
SSDパフォーマンス監視
データ読み込みプロセスの中でSSD がボトルネックになるのを避けるためにフルスピードで実行可能
iostat ツールを使用して、各トレーニング・プロセス中に SSD の I/O ステータスを観察します。サンプル・データのロード段階では、SSD はほぼフルスピードで動作できます。
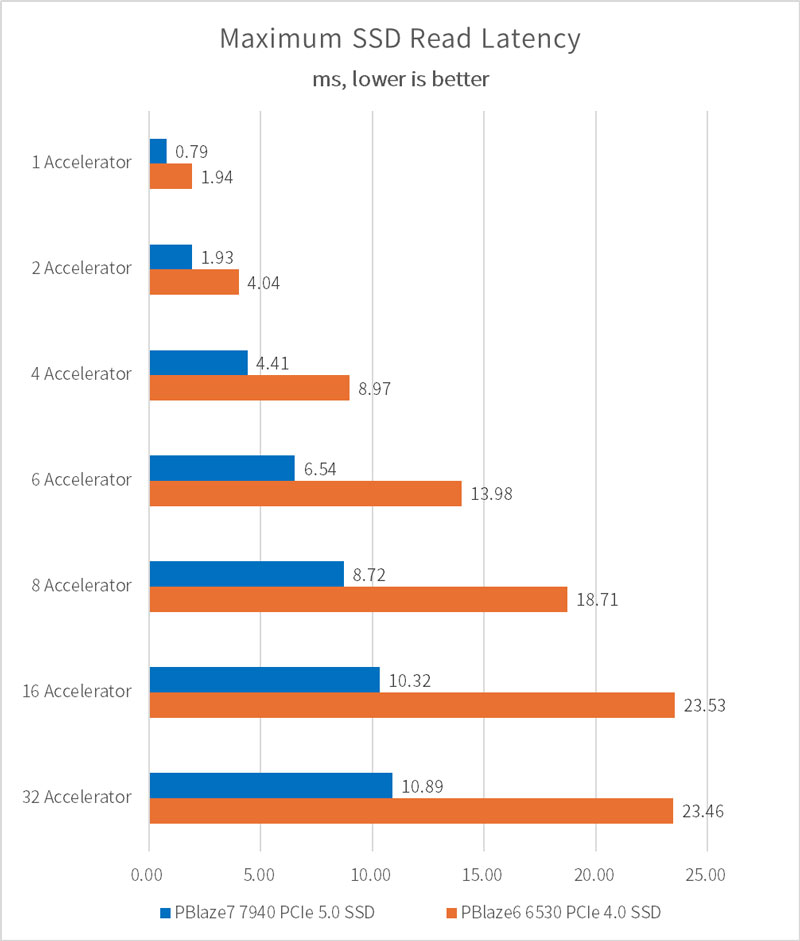
SSD の読み取り遅延は次のとおりで、ほぼ完全にロードされている場合、PBlaze7 7940 PCIe 5.0 SSD の遅延は PCIe 4.0 SSD より 50% 以上低くなります。