With the release of the MLPerf Storage v1.0 test results by MLCommons in September, a new wave of performance competition has swept across the storage industry, highlighting the significant role of storage in artificial intelligence (AI) workloads.
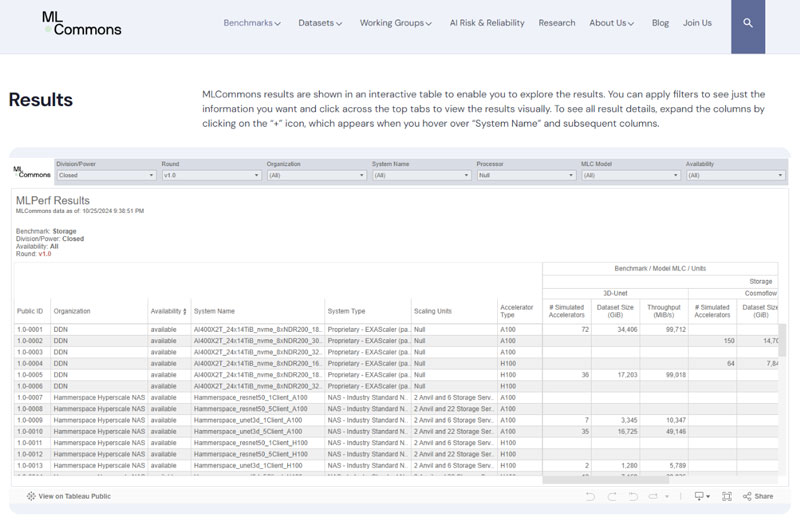
MLPerf Storage v1.0 Result Page (from MLCommons)
MLPerf Storage v1.0 essentially extends the DLIO Benchmark we previously tested. DLIO provides a fast, scientific approach to I/O performance measurement across various machine learning (ML) workloads. By adjusting parameters, it can simulate different GPU environments, helping developers optimize their storage for improved GPU utilization.
MLPerf Storage makes test results from different vendors and hardware configurations more referenceable and comparable by providing more rigorous and uniform guidance on parameter settings.
This time, we ran comprehensive I/O performance tests on our PBlaze7 PCIe 5.0 SSD using MLPerf Storage v1.0 software with default script settings. The test simulated NVIDIA A100 GPU, which, compared to the V100 used in previous tests, reduce computation time by over 50%, placing even greater demands on storage performance.

PBlaze7 series PCIe 5.0 Enterprise NVMe SSD
Test Platform
The dataset size used in the tests followed the recommendations of MLPerf Storage v1.0. If GPU utilization does not meet the specified standards, or other issues occur during the test that result in the test not being completed, the test will be terminated.
The test results indicate that, across 3 model training tests, the PBlaze7 series PCIe 5.0 SSD maintained a leading position both in direct performance comparisons with similar products and in comparisons of average GPU bandwidth across multiple storage and compute nodes. Below are the detailed test results:
UNet3D is a network for medical image analysis, with an average sample file size of 146MB and batch size of 7. The storage system needs to provide each GPU with nearly 1.6 GB/s of data bandwidth, with GPU utilization expected to exceed 90%.
We simulated the training process of 1 to 8 A100 GPUs respectively:
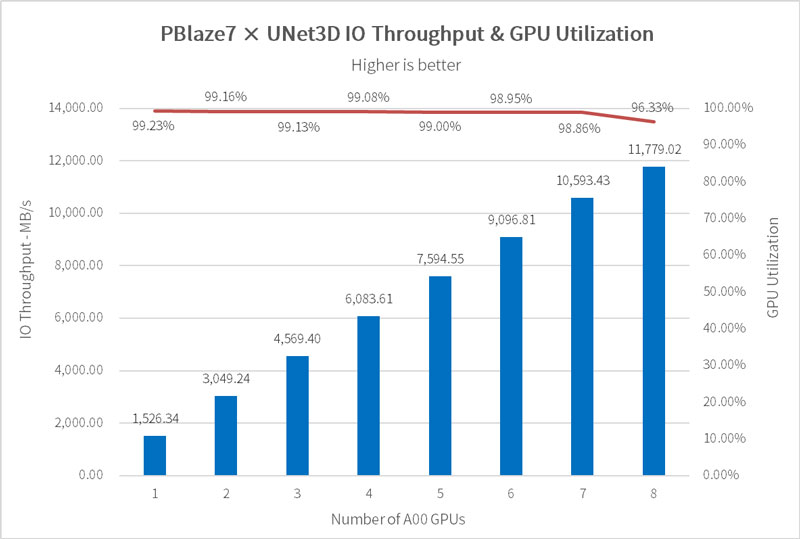
For comparison, the MLPerf Storage results show a Gen5 SSD performing at 9.26GB/s with 8 A100 GPUs, giving PBlaze7 a 27% advantage.
ResNet-50 is a deep residual network model with files around 100KB, each containing 1251 samples and a batch size of 400, which demands high random response speed and concurrent performance from the storage system, with GPU utilization needing to reach over 90%.
Simulations with 20 to 120 GPUs saw the PBlaze7 deliver 11.76GB/s for 120 A100 GPUs, maintaining 97.57% utilization.
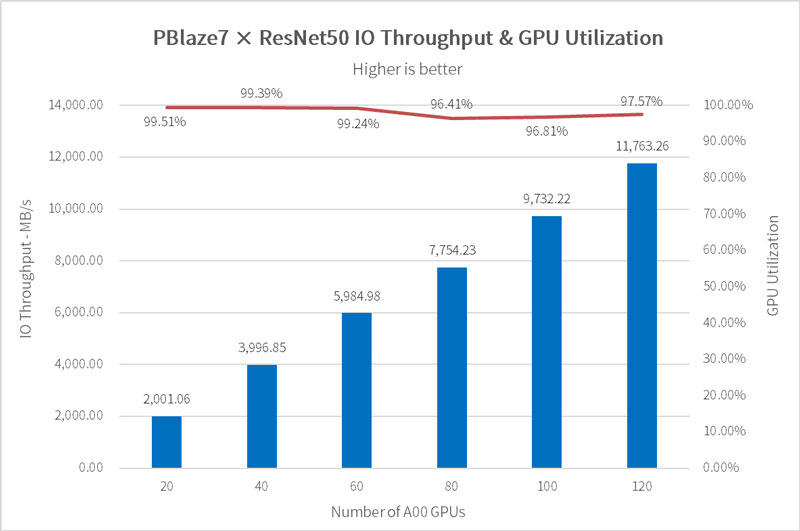
For reference, a Gen5 SSD listed on the MLPerf Storage site provided 10.45GB/s with 115 GPUs.
CosmoFlow, for cosmology research, involves large files averaging 2.8MB each. With GPU cycles lasting only 0.00551 seconds, high SSD random read speeds are crucial, with GPU utilization targets above 70%.
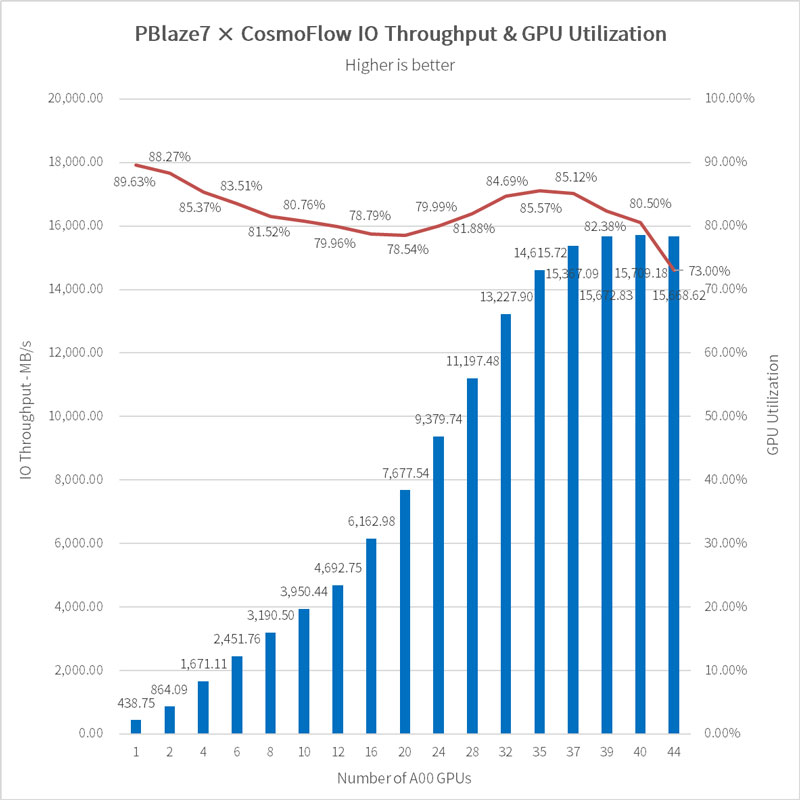
For comparison, a Gen5 SSD listed on MLPerf Storage performed at 7064MB/s with 20 A100 GPUs.
Due to platform performance and time constraints, this test did not simulate NVIDIA H100 GPUs, and some of the more extreme test cases were forced to be aborted. However, despite this, the PBlaze7 series PCIe 5.0 SSDs showed excellent performance in all three model training tasks simulating A100 GPUs, the PBlaze7 was able to securely rank in the top of the list, whether it was a direct performance comparison with similar products, or a comparison of average bandwidth shared by the A100 GPUs under multiple storage nodes and multiple compute nodes.
In typical AI training tasks, ensuring that each node does not become a performance bottleneck is the core of achieving efficient AI training. In addition to GPUs, HBMs, CPUs, and high-performance NICs, a high-performance NVMe SSD is also essential. Only in this way can we ensure sufficiently high IO performance at the source, bringing the most basic guarantee for efficient training tasks.


